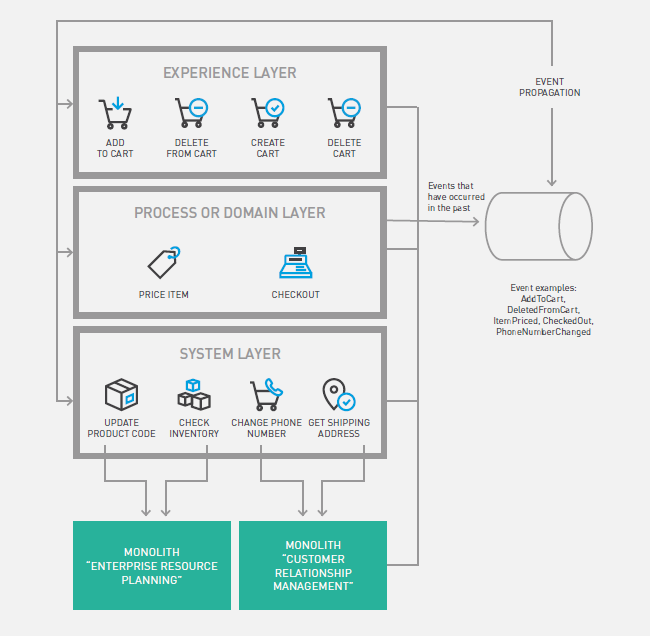
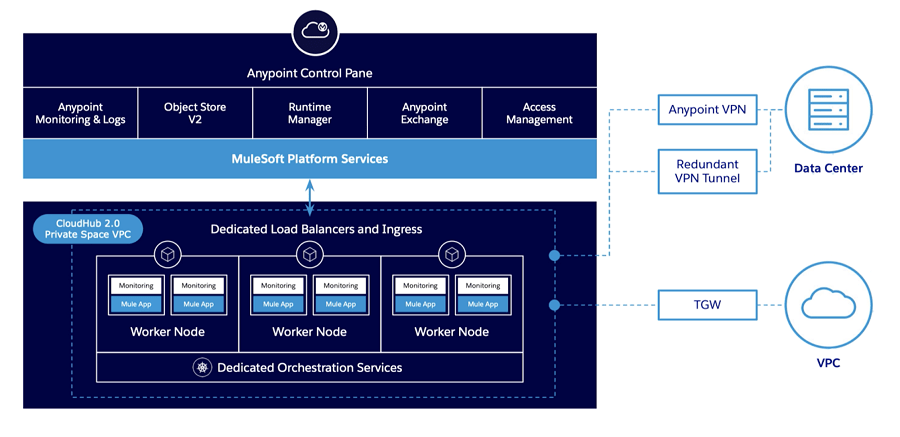
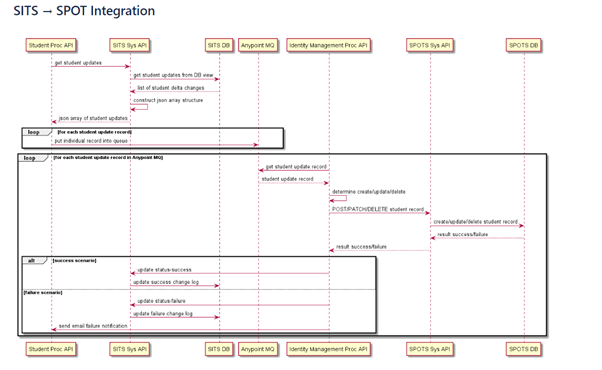
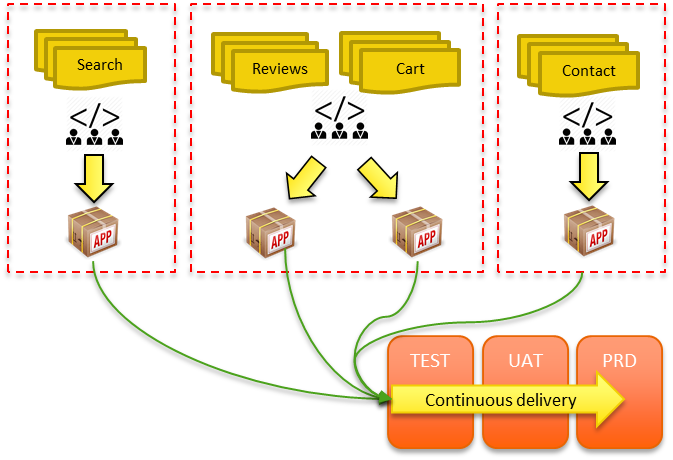
Introduction
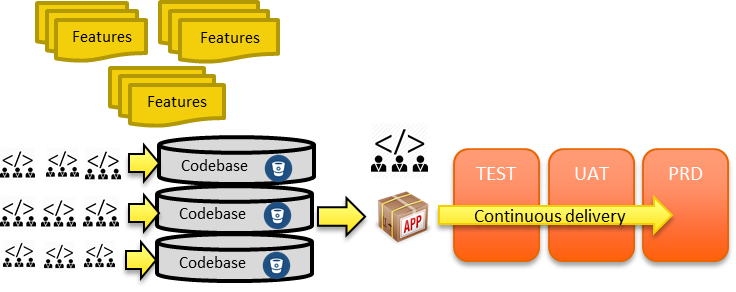
Integration paradigms are constantly adapting to shifting business needs and advancing technology. To tackle high complexity and the demand of today's data-driven environment, there are a few modern integration patterns. Check out several of the newest integration paradigms on the rise: