I’m going to pick up from last week’s post when we discussed the microservices definition, and looked at the alternative approach to microservices, aka the monolith. Make sure you read that before carrying on with this post.
Why is the microservices approach different? Let’s explore the main features one by one.
Business focussed
The main point of a microservice architecture is that each one of them need to encapsulate a specific business capability.
The focus shouldn’t be on the technology, but on the business case. This complies with the “single responsibility principle”; the service shouldn't be limited to mere data carrying, or reduced to CRUD responsibilities, but instead should encapsulate all responsibilities relevant to the business domain for which it was designed.
This is one of the reasons why the design phase of microservices can be more complex than for a monolithic application; dividing the business domain into exclusive context (this is a concept coming from DDD, or Domain Driven Design) is not a straightforward task.
The word ‘microservice’ itself can be misleading, as the size is not necessarily the compelling factor here, but rather the fact that it must be business focussed, and the choice of technologies we make inside is purely aimed to get the best for the purpose. Anyway, if we look for some sort of size guidance, let’s say it needs to be easy to comprehend for a single developer, small enough to be managed from a small team (see the “2 pizza rule” I mentioned in the previous episode), predictable, and easy to experiment with.
We can see the microservice as a vertical slice of functionality, a micro-silo with multiple tiers (including UI if necessary) and spanning across multiple technologies.
To make things a bit clearer, let’s make an example of a Music Search microservice. Just bear in mind, as I mentioned at the beginning you’ll find a lot different approaches in building microservices, so this is not intended to be the best solution - it’s just one viable solution according to the main microservices design principles.

Like many other microservices, this service exposes it’s functionalities via public REST APIs for other services to consume. But it also contains a set of UI widgets which could be embedded in a portal or external website.
The search capability does not span across other services - everything is included in here. For this reason, the storage technologies (in this example Apache Cassandra and PostgreSQL) are included inside the microservice; the search business logic is the only one accessing this data, so there is no reason to have them outside.
This way, the service is self-contained, as it includes all of its dependencies, isolated from the other microservices. All it needs to expose to the outside world is the public APIs and UI Widgets for others to consume or embed.
A single team is responsible for maintaining this whole service in its entire lifecycle, from development to release.
Open, lightweight, and polyglot
Sticking to Fowler’s definition, in a microservices architecture the applications should communicate with each other using lightweight and open protocols and payloads. This will guarantee the reusability and the performances of these services. So, depending on the pattern we choose (request-response, event-driven or hybrid) we will choose protocols like REST/HTTP, JMS or AQMP for example, and the payloads will likely use JSON.
A big advantage in this kind of architecture is not having a long-term commitment to any technology stack.
This gives us the possibility to choose the best language/framework suited for the purpose:

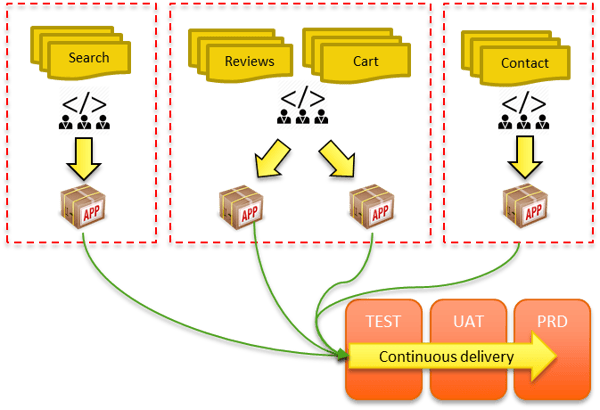
In this example, we might decide to implement:
- Search service using Spring Boot (Java), ElasticSearch as search engine and Cassandra as storage.
- Reviews service with NodeJS and Express, Solr as search engine and Mongo as storage.
- Shopping cart service with Scala and Spray, using Redis as a cache to store the cart items.
- Contact service with Dropwizard (Java based) using PostgreSQL as storage.
What do these services have in common? The answer is…nothing, apart from the fact they communicate between themselves via public APIs or events (we will get to this later on). Every microservice is free to adopt the language or framework that is most appropriate for this business domain. They also use different storage technologies. The concept of pan-enterprise data models and shared RDBMS does not apply anymore. It doesn’t mean RDBMS is gone for good (not at all), but it won’t be used anymore as a common way to share information, tightly coupling application together and preventing scalability.
You may notice that in the figure above the API (the service interface) is separated from the actual service implementation (which is tied to a technology); this is just to stress the importance of separating the interface of the microservice (you can see the API as the “door” to access the service) from its implementation (see ‘Loosely Coupled, Isolated’ section later on).
Scalable
By nature, microservices need to be easy to scale horizontally, to be able to handle flexible workloads.
In order to achieve this, they need to be reasonably small in size (perfect candidates to be distributed via Docker containers), isolated and stateless. Once these prerequisites are filled, we can leverage the features of the most popular container management platforms, like Docker Swarm, Kubernetes, or Apache Mesos, and scale our application easily:

When we’re talking about scaling, the financial factor needs to be considered; it’s much cheaper to scale out containers (inside the same physical or virtual machine), rather than scaling out entire machines. With monolithic applications, scaling the entire physical or virtual machine may be the only choice we have. This is because the components of the monolith cannot be scaled individually, and because there are many more external dependencies than individual microservices. Basically, we need many more resources (physical and financial) to be able to scale out.
Loosely coupled, isolated
Dependencies between services are minimised by defining clear interfaces (APIs), which allow the service owners to change the implementation and underlying storage technologies without impacting the consumers. This concept is not new at all; it’s one of the basics of Service Oriented Architecture.
Every microservice owns its own data and dependencies, so there’s no need to share this with anyone else; it contains everything it needs in order to work correctly. Let’s bear in mind though, in real life scenarios there may be the need for some microservices to share some sort of session, or conversation. In these cases, a possible solution is to consider using distributed caching solutions (e.g. Redis or Coherence).
But if we’re doing this the best possible way, the only resource a microservice is supposed to expose is its public APIs. (Note: this is not true if we adopt a full event-driven approach – more on this in the last episode).
The external dependencies the microservices usually have are the platform capabilities themselves. The functionalities to start, stop, deploy, monitor or eject metadata inside a microservice cannot be part of the service itself, but rather a feature of the platform we are using to distribute them.
Easy to manage
Now let’s have a look at microservices management from the DevOps point of view.
In a scenario with multiple independent applications, it’s likely that we’re going to have one dedicated team in charge of the development and deployment for each one of them.
In some cases, some services may be small and simple enough that one mid-size cross-functional team could maintain them all.
Since the services are business focused, the code base should be reasonably small to digest in a short time, and a new developer should be able to make changes on his first day on the project.
The deployment of a microservice is completely independent from the others, so whenever a change is ready it can be deployed at any time. The same team is responsible for development, testing and release, so there is no need for a separate team to take control of the release process.
If you think about it, this is exactly what DevOps is about; building, testing and releasing software happens rapidly, frequently and reliably, whereas development team and operations team tend to become the same thing.
Fault Tolerant
Keep in mind, in a microservice architecture every component is potentially a client and a server at the same time; every service needs to be able to work (or at least know what to do) when one of its dependencies (i.e. services it needs to call according to his business function), is down.
Since in distributed systems “Everything fails all the time” (as Amazon’s Werner Vogels reminds us), every microservice needs to be designed for failure, and circuit breakers need to be in place to prevent individual service failures to propagate through a large distributed system.
This implies that the larger our distributed application is, the more monitoring we need (much more than we need for a monolith), to identify any failures in real time.
Microservices: Service Oriented Architecture in disguise?
A common misconception is to consider these two approaches as alternative to each other, but actually, the microservices approach is actually based on a subset of a Service-Oriented Architecture (SOA) patterns.
As an architectural style, SOA contains many different patterns, like orchestration, choreography, business rules, stateful services, human interaction, routing, etc. Mainly, SOA is focused around the integration of enterprise applications, usually relying on a quite complex logic to integrate simple “dumb” services; a SOA architecture usually relies on centralised governance.
On the other side, microservices are more focused on decomposing monoliths into small independent applications, focusing on a small subset of SOA patterns, in particular choreography and routing. The microservices don’t need a centralised governance to work with each other, they simply regulate their behaviour to interact smoothly with each other. The integration logic is relatively simple (routing and nothing more), while the complexity is actually moved into the business logic of the service implementation itself.
Think of a SOA as big cross junction, and microservices as a crowd of pedestrians
As an example, think of a SOA as big cross junction, and microservices as a crowd of pedestrians. Without governance (i.e. traffic lights, signs, lanes) in a cross junction, cars would crash into each other and traffic jams would happen all the time. The system wouldn’t work at all. This doesn’t happen with a crowd of pedestrians; the pedestrians regulate their speed and behaviour smoothly and naturally in order not to crash into each other, and there is no need for a third party to tell them how to do it.
In summary, borrowing the definition of Adrian Cockroft (previous cloud architect at Netflix and now AWS) we can define microservices as a “fine grain SOA”:

In the next post, I will be taking a deeper look into some of the challenges of using microservices and possible approaches to decompose a monolith (I have covered the monolith applications in details in my first post). I will introduce event-based microservices and have a quick look at technologies and frameworks we can use to implement microservices, along with some of the most popular cloud platforms to distribute them.
Don't miss the third of my blog posts What are m
.png)