

Earlier this month, we were proud to join justice leaders, digital partners, and public safety professionals at the Modernising Criminal Justice conference 2025. Hosted at the QEII Centre in London, just a hop, skip, and a jump away from iconic sites such as Big Ben, Westminster Abbey, and the London Eye, the event brought together voices from across the justice system, from arrest through to release.
Breaking the silence. Fixing Firearms Licensing.

The recent BASC article "Silence on Firearms Fees Speaks Volumes" highlights what many in the shooting community already knew all too well: the firearms licensing system is buckling under pressure, with growing backlogs leaving applicants in limbo for months on end.
Tech
Building with Agentforce in MuleSoft Anypoint Code Builder

It’s been a while since my last write up on MuleSoft Anypoint Code Builder. While several new features have been introduced this year, I want to focus on MuleSoft’s artificial intelligence (AI) integrations. Let’s be honest, AI has been a hot topic for a while and isn’t going away anytime soon. So in this blog, I’ll guide you through using the Agentforce Generative Flow feature in Anypoint Code Builder and also share some practical tips along the way to help you get the most out of it.
Business
Can everyone afford innovation?

One morning, while practising my morning mindfulness using Headspace, my wandering mind started to think about conversations I had recently. The meditation was called Feel 1% Better. This struck a chord with me because people often struggle to achieve success of 100% or view anything less as a failure.
Business
Motivating the next generation: a day in tech for young minds

Introduction
We recently held an event called Get into Tech as part of our Corporate Social Responsibility (CSR) effort, inviting students aged 16 and 17 to participate in an intensive day of learning and exploration in the field of information technology.
Tech
October 2024 Anypoint Code Builder Release

Have you checked out Anypoint Code Builder lately? There has been another major release since my last blog, but don't worry, I’m here to guide you through the recent changes.
Business
The business user's guide to Data Cloud
We know that effectively managing the ever-growing and quickly-changing world of customer data can feel overwhelming. Salesforce Data Cloud is here to change that! But what exactly is it? And even more, why should it matter to your business? Turns out that Data Cloud isn't just for those working in technical roles - so how can it have an impact for business users? Let’s dive in and break it down!
Tech
Using AWS service role in CloudHub 2.0
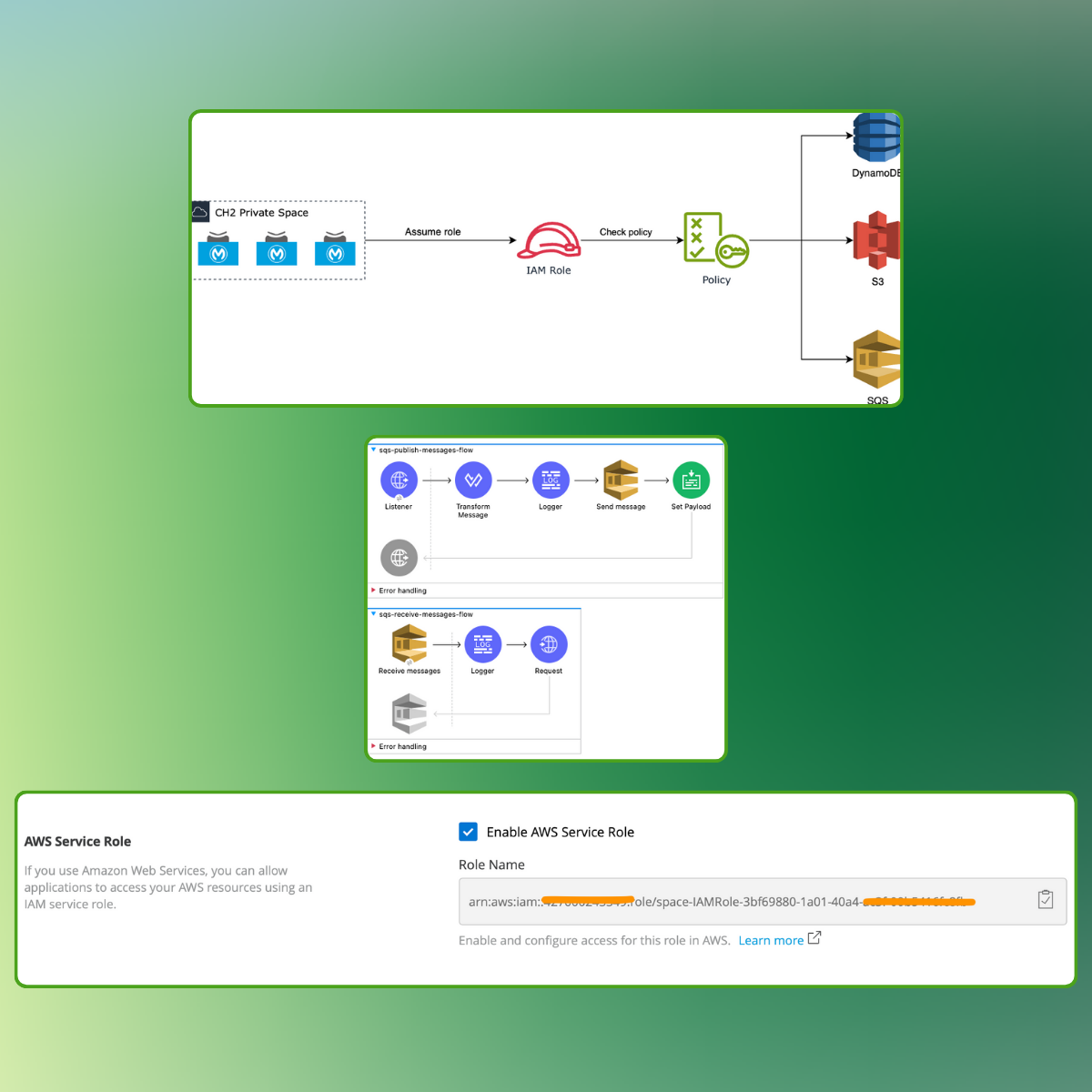
AWS Service Roles allow services to securely interact with other AWS services on your behalf by assuming roles with the necessary permissions. This simplifies access management and reduces the need to handle long-term credentials.
CloudHub 2.0 works on top of an AWS EKS service, so we can leverage AWS Service Roles to connect our APIs with many other AWS services used by our integrations, such as SQS, S3, DynamoDB, Secret Manager, etc.
In this article, we will see how it works and how to implement it.
Topics:
Technical training
Tech
Continue Reading
Prioritising mental health: the connection between mind and body

In today's fast-paced world, we often hear about the importance of mental health. Yet, how often do we consider the profound connection between our mental and physical well-being? On last week's World Mental Health Day, as we reflected on mental health and its importance, I wanted to shed light on the often-overlooked relationship between mental and physical health, and why taking care of both is essential for leading a fulfilling life.
Tech
Data Cloud in higher education - more than just a system of record
In higher education, managing student data is often seen as a challenge of consolidating records across various platforms - from admissions and financial aid systems to student management portals and alumni databases. For many institutions, the complexity of these systems leads to fragmented data, making it hard to get a unified view of students and make timely, data-driven decisions.
