
Insurance claims, invoices, various forms and applications - every organisation deals with a wide range of unstructured documents. Although manual extraction of critical information is still typical, many departments invest in automating such processes.
Amazon Textract, a machine learning (ML) based service, goes beyond simple optical character recognition (OCR) to identify and extract data from scanned files.
Today, I will demonstrate how to use MuleSoft RPA, AWS Intelligent Document Processing (AWS IDP) component in MuleSoft RPA Builder and Amazon Textract together. We will fully automate the process of reading an email, processing its attachment and using its data to create a new record in a CRM system.
The process
I started by creating a Process Automation (Bot) to read emails and save the attached Invoice.pdf in a specific folder. My Bot will extract data stored in the invoice, including the vendor's name, contact information, invoice number, and purchased items (description, quantity and price). To be precise, the Bot will call the AWS IDP component in MuleSoft RPA Builder to do the job. Once the data is extracted, the Bot will use the information to create and populate a new Invoice record in Zoho CRM.
Note: For the sake of simplicity, I am not explaining how to create Zoho CRM and AWS accounts. You can use both accounts with a free trial period.
Bot tasks
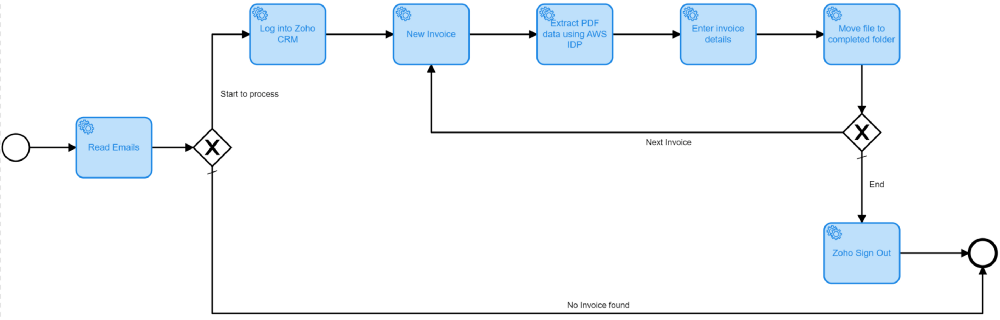
I have added the following RPA Bot Tasks to the process automation:
- Read Emails - read emails and save the attached PDFs in a specific directory (To Process).
- Log into Zoho CRM.
- New Invoice - navigate to the Invoices page.
- Extract PDF data using AWS - connect to AWS Service to extract data from each PDF file saved to the "To Process" directory.
- Enter invoice details - create and enter the invoice details.
- Move the file to the "Completed" folder. If there are more files to be read, go to step "3 — New invoice".
- Sign out Zoho
 Bot tasks
Bot tasks
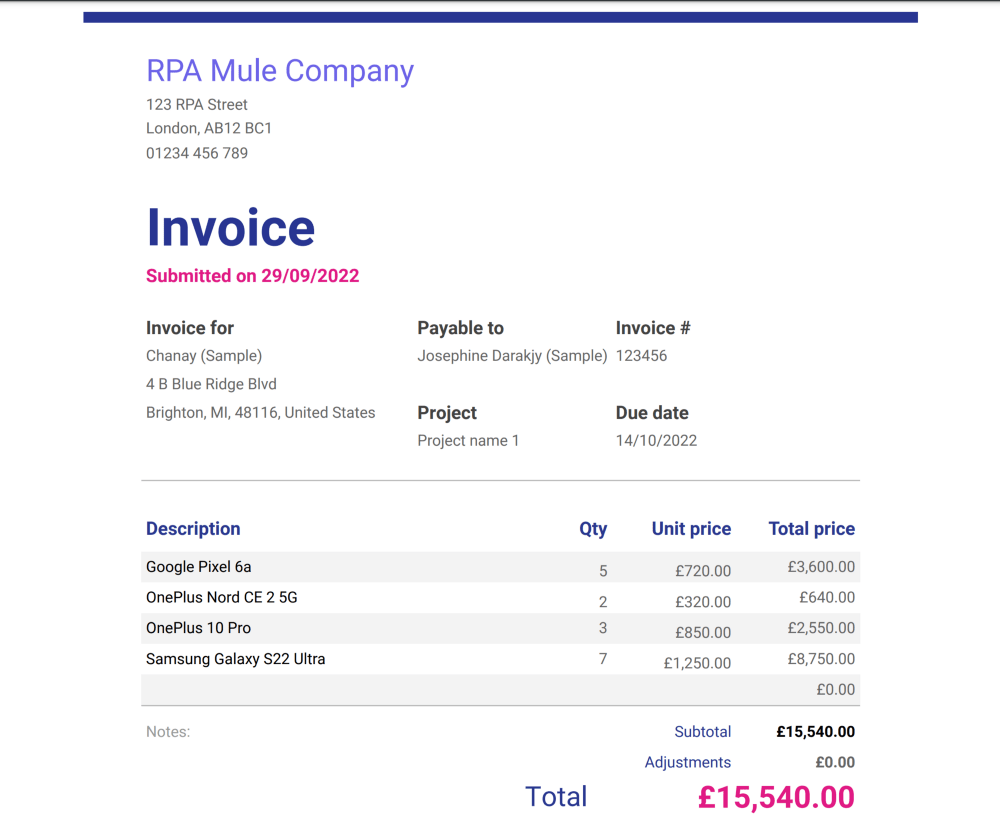
Here is the format of the document I am using for testing - Invoice.pdf.
Extract data from PDF using the AWS IDP component
ERP Docs With AWS
![]() ERP Docs with AWS in MuleSoft RPA Builder
ERP Docs with AWS in MuleSoft RPA Builder
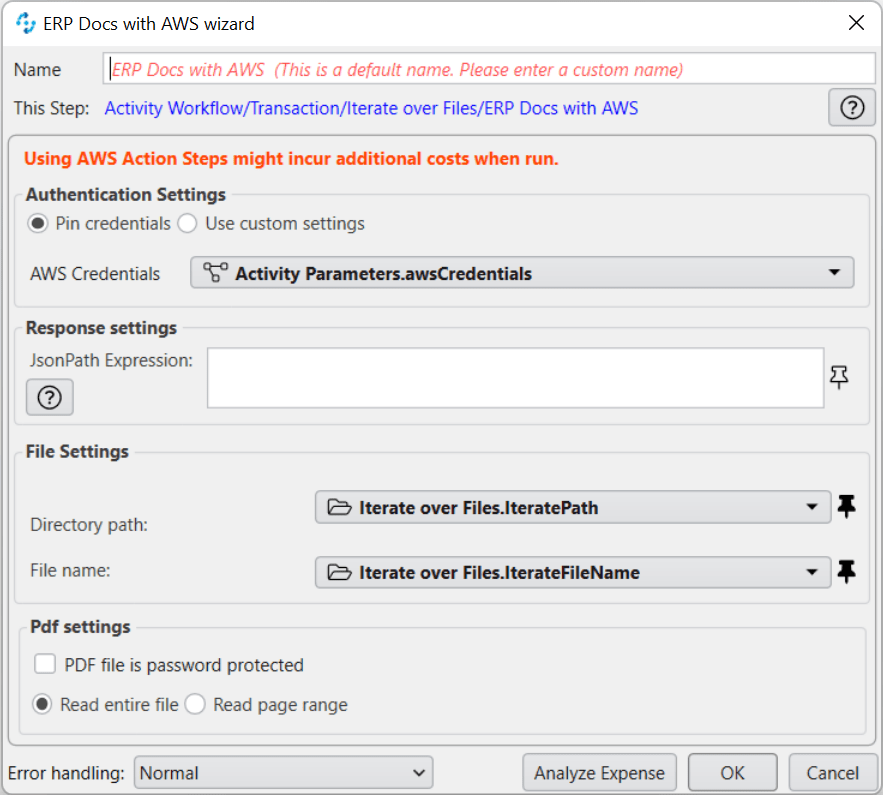
The ERP Docs With AWS component uses the Amazon Textract service to analyse invoices and receipts and extract relevant data in JSON format.
Note: You must have an AWS Account.
The configuration is simple and requires the AWS Client ID, Client Secret, Region Endpoint and the file to analyse. The supported file types are PDF, JPEG, and PNG.
The AWS Service has three types of responses:
- Raw Text - the extracted raw text of the document.
- Normalised JSON - the parsed result based on the normalised result and defined JSON path.
- Raw Json - the complete AWS response.
JSON Query
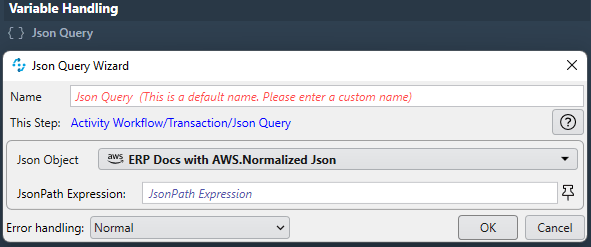 JSON Query
JSON Query
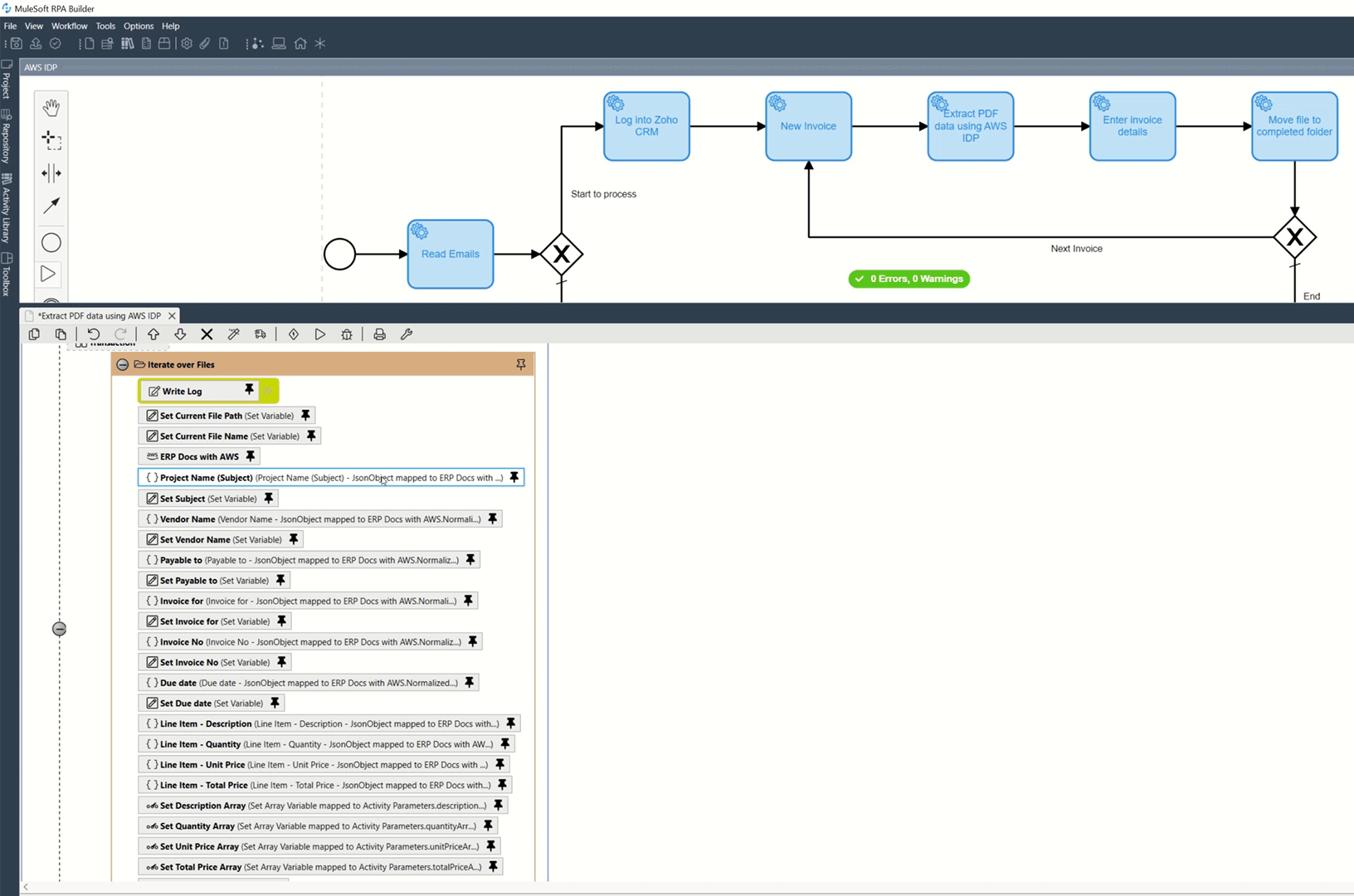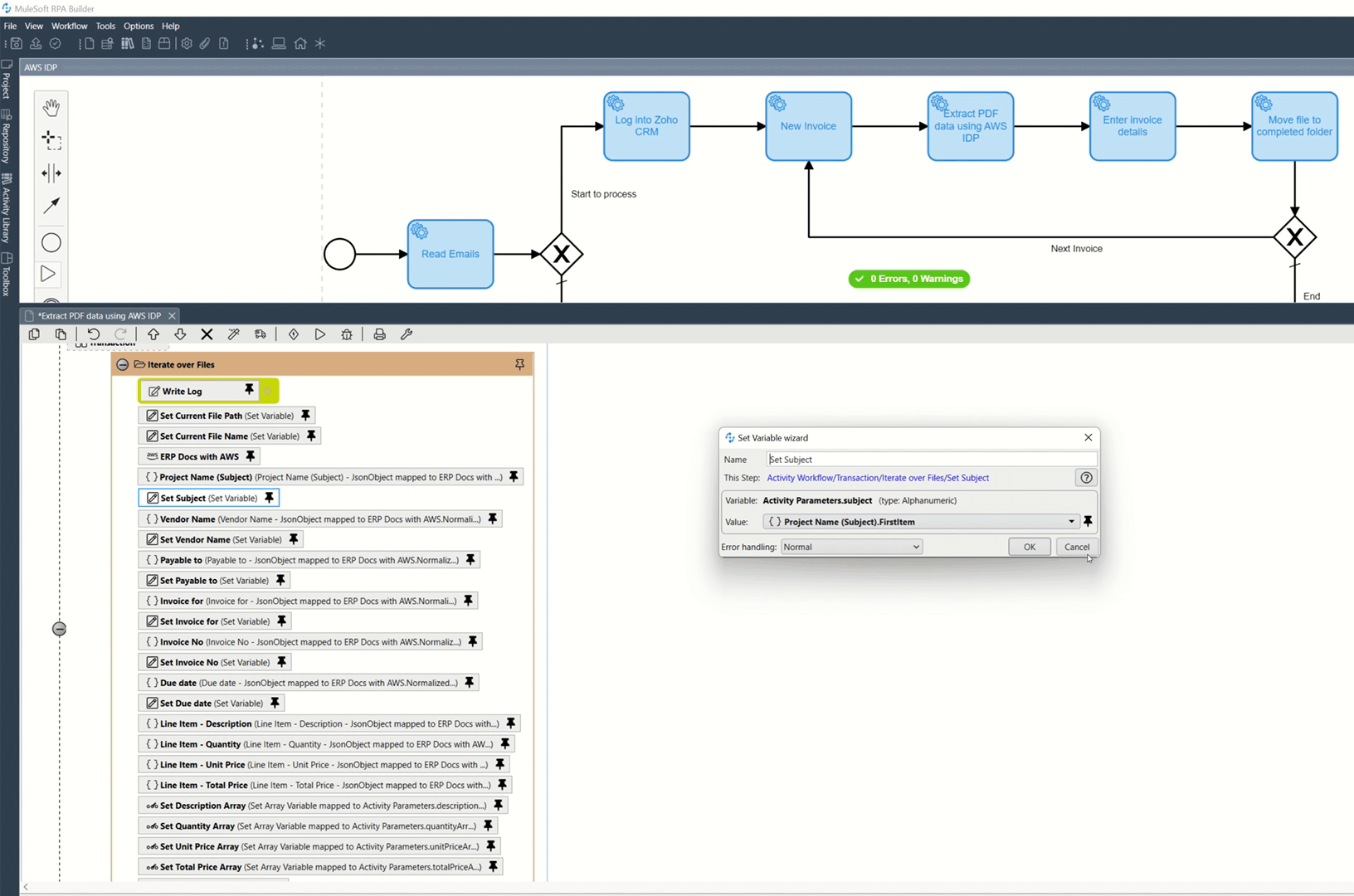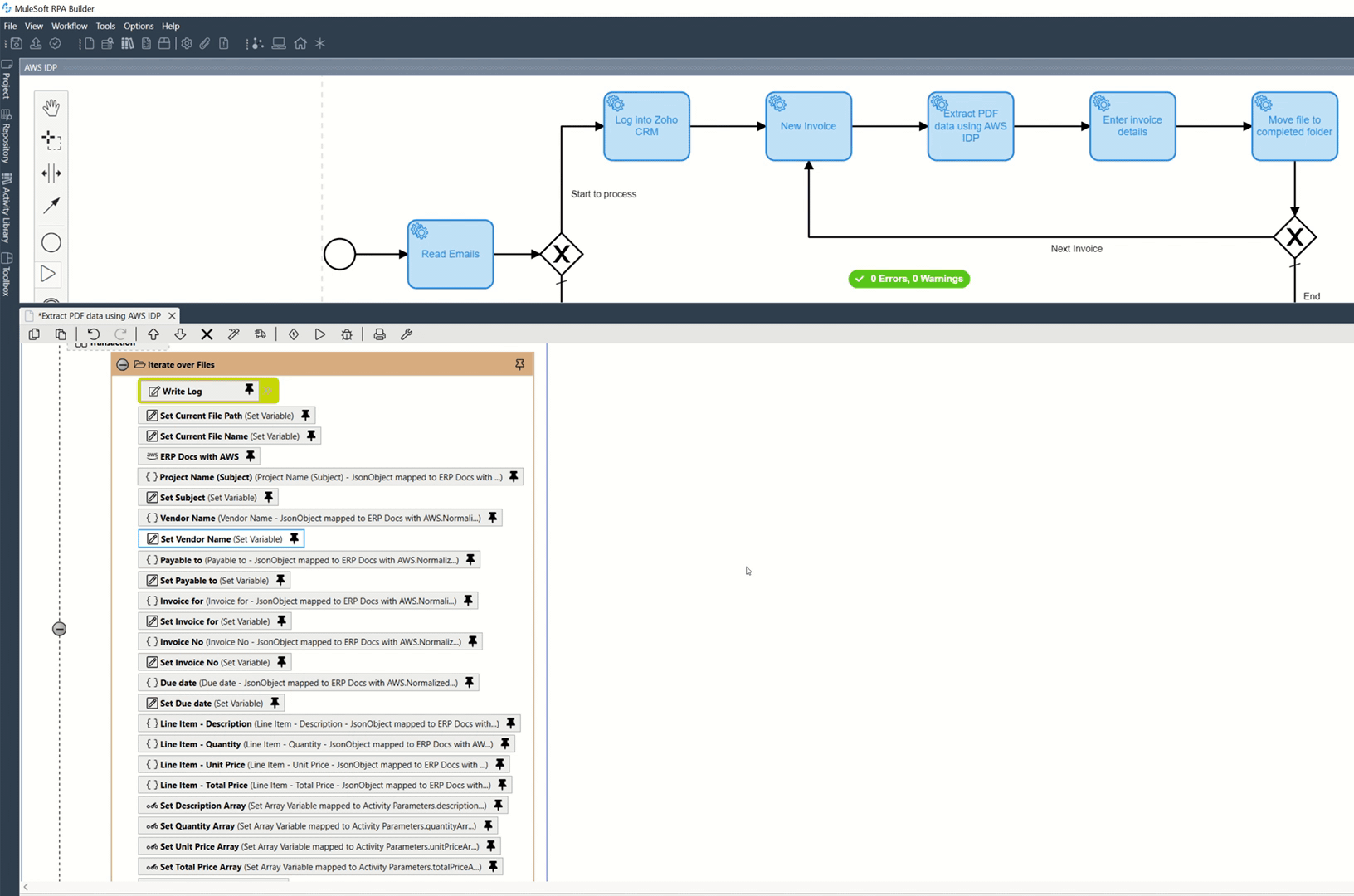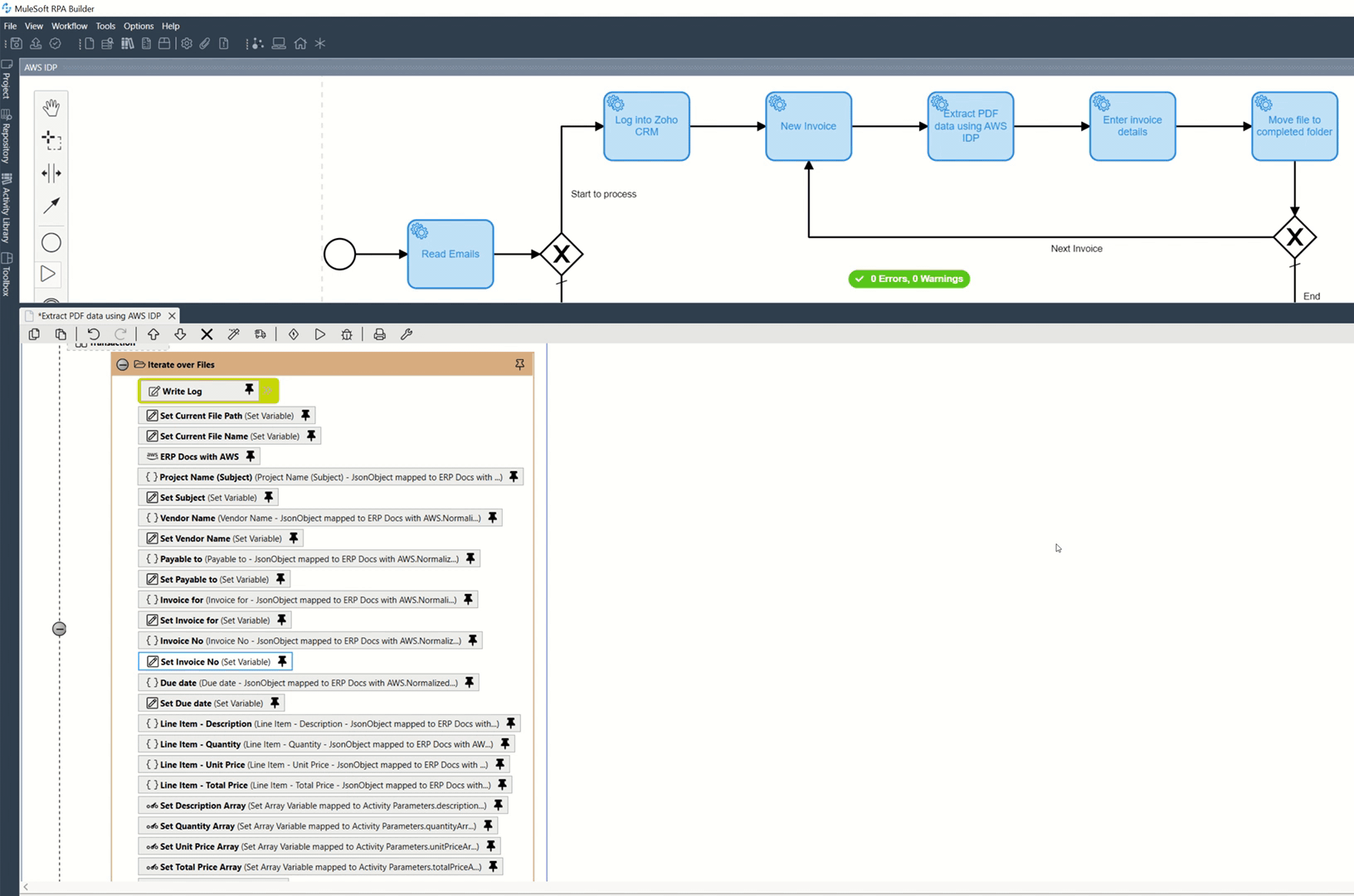
The "JSON Query" component extracts data from JSON with JSONPath Expressions. I used the online tool https://jsonpath.com/ to create and test the expressions.
By setting JSON Object as Normalized Json, the AWS Service response will look like this:

Below are some examples of evaluating and getting the values for Vendor Name, Project and Invoice Number.
- Vendor Name: $..SummaryFields[?(@.Type==’VENDOR_NAME’)].Value
- Project: $..SummaryFields[?(@.Label==’Project’)].Value
- Invoice Number: $..SummaryFields[?(@.Type==’INVOICE_RECEIPT_ID’)].Value
 JSONPath Expressions
JSONPath Expressions
Once I evaluated the values, I saved them in their respective variables.
 JSON Query
JSON Query
Next, the Bot logs into Zoho CRM to create a new Invoice using Click Web Element and Keystrokes components.
I have recorded every step of this exercise - executing the Bot, sending the Invoice.pdf to AWS Service and, extracting the data from the returned JSON, opening and creating a new Invoice in Zoho CRM. Enjoy the action:
MuleSoft RPA: Extract PDF data using AWS IDP in MuleSoft RPA Builder
What do you think? What was your experience of using AWS components in MuleSoft RPA Builder? Let me know in the comments.
I hope you liked this post.


.png)
