The old way
I'm going to let you in on a secret. I learnt my trade in a traditional software testing consultancy - I'm talking a waterfall approach to test planning, test case definition and test scripting. Over the last 5 years at Infomentum, I've evolved and have worked hard to optimise Infomentum's testing practices to suit our agile development environment.
Going back several years, Infomentum's Test Analysts would document detailed test scripts with extensive steps and expected results against each user story, and store as a test suite in a dedicated test management tool. At the time, that level of detail was useful. The problem was, we were finding that scripts were taking a long time to produce, quickly becoming outdated, and the effort required to maintain them was just not sustainable. As the volume of scripted tests increased, so did the time needed to execute a regression test; and that increased the time needed to release.
We dabbled with test automation, but at the time drew no connection between the tests that we'd automated and the tests that were executed manually, and the relevancy and coverage of the automated tests was not appreciated by the wider team.
Valuable Test Analyst time was being taken away from what mattered most; hands on testing with the product under test, identifying, raising and resolving issues, and ultimately decreasing risk. We needed a way to drastically shift our testing time in the sprint from a Documentation to Test Execution ratio of 4:1 to 1:4, with a more exploratory approach to testing - whilst continuing to satisfy our clients’ needs to understand our test coverage and see tangible test evidence.
The new way
Behaviour Driven Development (BDD) is becoming more and more popular among agile development teams. It's a methodology used to gain a common understanding of product requirement by describing the desired behaviours of the product. Cucumber is a tool to test the behaviour of your application, described in special language called Gherkin. Gherkin is a Business Readable, Domain Specific Language created for behaviour descriptions. It gives you the ability to remove logic details from behaviour tests. Gherkin serves two purposes: serving as your project’s documentation, and automated tests by defining as a sequence of Given, When or Then steps grouped as ‘Scenarios’ against a given product ‘Feature’, for example…
Feature: Refund item Scenario: Jeff returns a faulty microwave Given Jeff has bought a microwave for $100 on 2015-11-03 And today is 2015-11-18 And he has a receipt When he returns the microwave Then Jeff should be refunded $100 |
Before I go on, I should say that I'm aware that BDD is a technique for defining product requirements, and not specifically designed for being used as test cases. That said, at Infomentum, we've found scenarios to be an effective reference point during development and testing of a user story, to ensure that it's in line with the desired behaviours captured from the product owner.
Going through the process of collaboratively defining the scenarios really benefits from the analytical mindset of a tester, which is needed during test case design. The tester is in the best position to challenge with those ‘what if’ conditions that might not have been considered. The iterative approach to defining the scenarios allows for simultaneous test design and execution, as per the exploratory testing mandate, meaning the feature description and test documentation can evolve as one as each user story goes under test. Documentation is never out of date and always has a description of the desired behaviour of the product features at any moment in time.
To provide greater visibility and traceability, we load our features and scenarios into JIRA, linked to user stories. We use the issue status to track test execution progress. Watch this space for a future article on how we go about this - and how we utilise the JIRA API to integrate JIRA with our test automation framework, including dynamic generation of feature files.
The Infomentum test team use the scenarios as charters for exploratory testing, and utilise JIRA Capture to record output from our exploratory testing sessions. As we spend more time with the product, our understanding of it develops, which often leads to refinement of the scenarios in conjunction with the product owner.
But of course, we work in an agile environment. All modules are subject to continuous refactoring. That means it's not satisfactory to validate these behaviours as a one off exercise; the development team and the product owner need assurance that they won't break anything in the process of continuing to develop and re-factor product features. It's also not sustainable to run extensive manual regression tests. If you are not automating these tests, and are conducting the bulk of your regression tests manually, you are in fact introducing a form of technical debt, as the time required to test a release increases linearly as more functionality is added.
Cucumber JVM is our technology of choice for implementing these scenarios as automated tests, and for providing the development team with rapid feedback throughout development. Our Java based test automation framework utilises libraries like Selenium WebDriver to support our automation needs, and it's also heavily integrated with JIRA for recording test results. We'll expand on this in future articles.
Some lessons learned along the way
Here's some key things that we've learned from working with BDD and Cucumber over the last couple of years, and implementing scenarios as automated tests in a JAVA framework. All of our recommendations are concerned with keeping your feature files and code more succinct and straightforward to maintain:
- Define conventions for expressing steps – Avoid having multiple phrases for performing the same action or verification for example;
When I press the Search buttonWhen I click on SearchWhen I click on the Search button |
The meaning of all the above phrases is the same, though for Cucumber they are interpreted differently. By defining a set of rules and being consistent, your automation code will be a lot more manageable. Initially this requires a lot of reviews and refactoring, but after some time it becomes a habit - similar to the way developers adopt coding conventions to make sure that they can understand each other’s code. Try to reuse text instructions as much as possible – the more similar step definitions you have, the more difficult it will be to maintain the code base.
- Use parameters in your definitions – Reusing text instructions is powerful, as Cucumber allows you to vary some part of your step instructions. The step definition method in the code is bound to a step instruction in feature files using regular expression with back-linked variables. E.g. for instructions like:
When I add 4 more bananasWhen I add 3 more apples |
…we don't need to bind both instructions with separate step definition methods, we can bind both to the following regular expression:
// Calculator addition@When("I add (.*) more (.*)$")public void addAnAmmount(String numberToAdd, String subject) throws Exception { calculator.performAddition(numberToAdd); System.out.println(subject);} |
In Cucumber the text in quotes will be passed as parameters, which can then be used in an automated test function you define. This can be used to drastically decrease the number of step definition methods required.
- Use an appropriate level of detail in scenario steps and create modular building blocks that can be collated together – restrict the steps in the scenario to what is actually being tested in any given scenario, to avoid your scenarios becoming too long. A simple example is a login. When writing a scenario to test the login, you might describe it as;
When I enter the username “fredbloggs”And I enter the password “password”And I click the login buttonThen I am logged in as “fredbloggs” |
For all subsequent scenarios that are testing other areas this could be simply described as;
Given I am logged in as “fredbloggs”When I … |
In this example, we put instructions from the first test and wrapped them with the single instruction. But the main idea is that if we don't care about how we do some actions, and we just need the result, then we can use more high-level instructions.
By building our step definitions in this way, we make a layer of reusable functions which represent some domain layer. These functions can be grouped together like building blocks to perform a more complex function.
- Focus on behaviours not implementation - Scenario steps should be a description of system and user behaviours, and in most cases not describe each and every click required for the user to achieve that goal. Try to avoid coupling your scenario descriptions too tightly to the way that a user story has been implemented - otherwise the description of the desired behaviour will be impacted every time this is tweaked.
For example, define a step as;
When I add 2 pencils to my basket |
And not;
When I click on PencilAnd I enter 2 in the quantity fieldAnd I press the “Add to basket” button |
- Define a structure that is maintainable – if you keep all of your detailed automation code in a single step definitions class, you will quickly find that you are repeating a lot of code, and it becomes difficult to maintain - especially where you are using the same Selenium functions over and over again. Ideally you'd have a separate definitions file for each piece of functionality that you're testing. However, since we need to define our Webdriver, and reference the same driver through every step, all of our definitions need to have access to this driver.
Our structure is therefore to have a single step definitions file with a package of action classes split by different areas of functionality that we are testing within the application (e.g. login, car search). All of the complex automation logic resides in these action classes, and is split into logical functions which can be reused across multiple step definitions. Each step definition function is extremely lightweight, and simply acts as a binding layer between the feature runner, and some functions within the action classes. A utilities package is home to classes containing common functions required across all/multiple action classes, such as Selenium WebDriver, for which there's a class containing all the required functions. So that a single scenario can utilise functions across multiple action classes, and the same instance of Webdriver be used, the Webdriver class is instantiated from the StepDefinitions file and shared with each action class. That means they all have access to the suite of functions, and the same browser instance can remain open as the scenario moves between different areas of functionality. We have a number of other common utility classes for querying databases and calling web services for example.
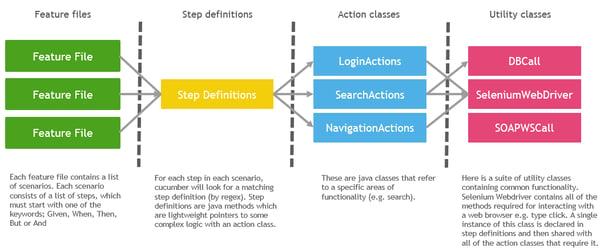
We've found that this structure is the best way to keep your code functions modular, and to avoid duplicated code. (Ref. https://www.coveros.com/819/)
- Use Cucumber for non-functional tests – Cucumber is clearly well suited for verifying functional behaviours, but we've also experimented with validating desired non-functional behaviours. A simple example is to capture the time taken for a search function to return results to the interface and assert that it responds within the NFR upon each execution. We've also used Cucumber and our framework in accessibility, security and cosmetic comparison tests - but that's another blog post.
- Make your @Then verifications scratch beneath the surface – working within an open JAVA framework is useful in the freedom that it creates. Most of our automated Cucumber tests are in part at least browser based, but not all. We also interact with web services, APIs and databases. This is particularly useful in the @Then steps to verify the outcome of the scenario beyond what is shown in the front-end. For example, we might check the order status has been updated correctly in the database, or that an exposed API is returning the correct order status, to be completely satisfied with the scenario end to end.
- Use scenario outline and examples to increase test coverage – Cucumber has a useful feature called Scenario outline which can drastically increase your test coverage for similar tests with different combinations of inputs. In the scenario outline steps, you can replace fixed values with variable <placeholders> and then populate a table of “Examples” beneath the outline. The table contains a set of values for each variant in each row of the table. The more rows we add, the more cases will be checked. The scenario outline will be executed for each row in the table, and each run uses data from the appropriate row. This can be a more succinct way of defining a group of very similar scenarios, e.g. scrolling a carousel, pagination, search filters etc.
Scenario: eat 5 out of 12 Given there are 12 cucumbers When I eat 5 cucumbers Then I should have 7 cucumbersScenario: eat 5 out of 20 Given there are 20 cucumbers When I eat 5 cucumbers Then I should have 15 cucumbers |
Scenario outlines allow us to more concisely express these examples through the use of a template with placeholders, using Scenario Outline, Examples with tables and < > delimited parameters:
Scenario Outline: eating Given there are <start> cucumbers When I eat <eat> cucumbers Then I should have <left> cucumbers Examples: | start | eat | left | | 12 | 5 | 7 | | 20 | 5 | 15 | |
- Use background steps to avoid unnecessary repetitive steps in your scenarios – where all scenarios for a given feature have a common set of steps, it's not necessary to repeat those steps in each scenario; they can be defined at the feature level. These common steps will then be executed before any child scenario is executed, and the scenario steps will take over from that point. This is useful for navigating the user from the default home screen, to the appropriate location for the context of the feature, and logging in if necessary.
Feature: End user should be able to see the news and views listing pageBackground: Given I am on the homepage And navigate to the News and views homepageScenario Outline: Using the filter on the news page When I use the Regions & countries filter to select only "<regions>" And select "<type>" in the Type filter Then I can see a reduced number of articles Examples: |regions|type| |South of England|News| |
- Do not use Cucumber for white box unit testing – Cucumber tests are written in business language to define the end to end behaviours of a system. Unit testing is done by developers for developers and are designed to validate a single code function. Readable tests are not an advantage here, as developers understand the code and purpose of each unit test well.
In summary
Cucumber has provided a way to increase the visibility of our tests; it expresses them in a language consistent with the wider team, and the client, creating a shared understanding about what is being delivered and tested. By using Cucumber, we've been able to meet our objectives of dramatically increasing time spent in test execution, and found an efficient way of documenting our testing and ensuring it's up to date.
Look out for my next article on how we took our Cucumber integration to the next level with Cucumber JVM automation and integration with JIRA.
.png)