In my last article, The evolution of test documentation; lessons learned from implementing Cucumber, I explained two things. Firstly, how we at Infomentum have adopted Behaviour-Driven Development to define test scenarios, and secondly, how we use Cucumber JVM as an implementation platform for running these scenarios as automated tests.
Like many organisations running agile projects, we have Jira as our activity hub for managing and tracking them. So, we were keen to use Jira to define and store our Cucumber features and scenarios; we wanted all the aspects of a user story (defects, tasks, tests), and their current status, to be seen in a single view (particularly helpful when evaluating the definition of done).
In this article, I'll explain how we went about utilising the Jira REST API in our bespoke test automation framework, to enhance our automated test capability, and give more visibility to our automated tests. This screenshots below show you how.
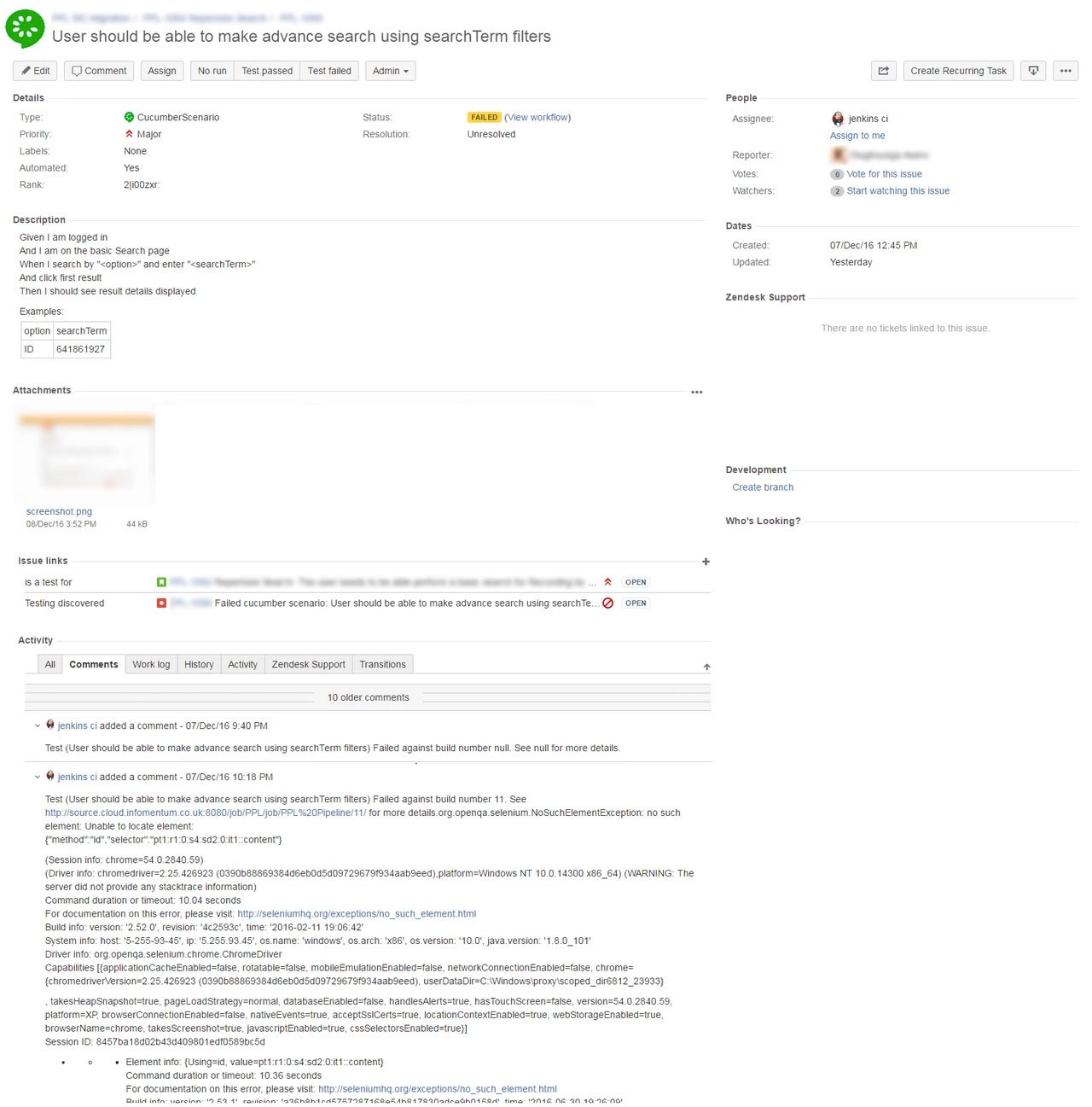
The following diagram summarises how we map issues of different issue types, and their relationships, using Jira issue links. This means we can view the full picture of a story, and all of its dependencies and impediments, when we're planning a sprint. It also lets us progressively evaluate the definition of "done" when we're executing a sprint.
Step 1: Configuring your Jira instance
You'll need a hand from someone who has access to Jira's admin screens, and knows their way around them. (I won't go through the details here). On your shopping list, you'll need to include the following:
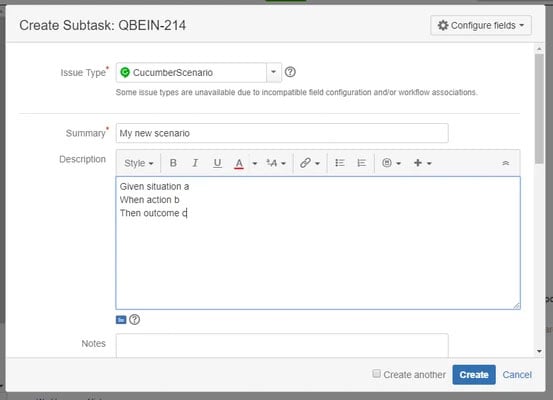
- Creation of a new parent issue type 'Feature', and a new sub-task type 'Scenario' (and have these added to your project issue type scheme);
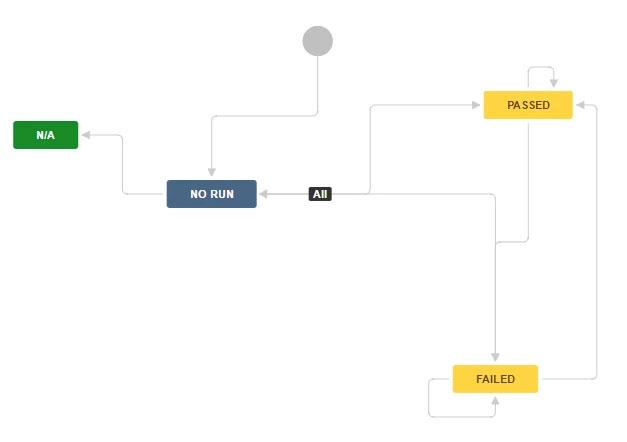
- Creation of new basic workflow to drive the testing status of a Feature and its Scenarios (see below), with the following status: No run, Passed, Failed, N/A;
- Creation of a new custom field, to indicate if the scenario is automated or not (Yes/No). Take note of the Jira custom field ID - you'll need this later;
- Creation of a new screen scheme, associated to these issue types. This includes the following fields: Summary, Description, Labels, Automated (Yes/No), Priority, Linked Issues;
- Creation of a new issue link type that associates Cucumber scenarios to stories/requirements, e.g "test coverage";
- Creation of a new issue link type, that associates defects with Cucumber scenarios. For example: "Discovered whilst testing" (if you don't already have this);
- Optionally, you might want to create additional issue types and issue links (you can see this n the diagram above).
If you manage to get that lot done, then you've survived the first test!
You can use this setup even if you only automate some of your Cucumber scenarios, or if you don't automate any at all. It's still a really useful way to update your test results when you're executing a test manually, during a manual test execution.
![]()
Step 2: Creating feature files dynamically from Jira
As a Cucumber user, you'll be all too familiar with what a .feature file looks like. Before our integration with Jira, we were writing these straight into in an IDE or a notepad. We then squirreled them away in a code repository, where they started collecting dust, and disappeared from the product owner's sight.
We now have our features and scenarios defined in Jira, and our product owner uses issues and sub-tasks. Another change is that the .feature files are written dynamically, on run time, which is has a number of plus points:
- The development team, product owner, and business users have a much better visibility of features and scenarios. We’re also using issue links, so they can see the relationships between scenarios and other stories. All of this makes it much easier to evaluate the status of a user story, and to understand the requirements.
- Our testing teams can expand and adjust test sets 'on the fly', without committing code, by adjusting the Jira issue labels.
- We can also define new tests 'on the fly', to a certain extent. This works if you use terminology that's already been defined in your StepDefinitions file.
- We can track the status and history of a scenario through Jira issues. This includes tracking the point where the scenario passed, or failed, under a certain build number. We can also see why this happened.
This diagram summarises how we map a Jira issue element to a cucumber .feature file.
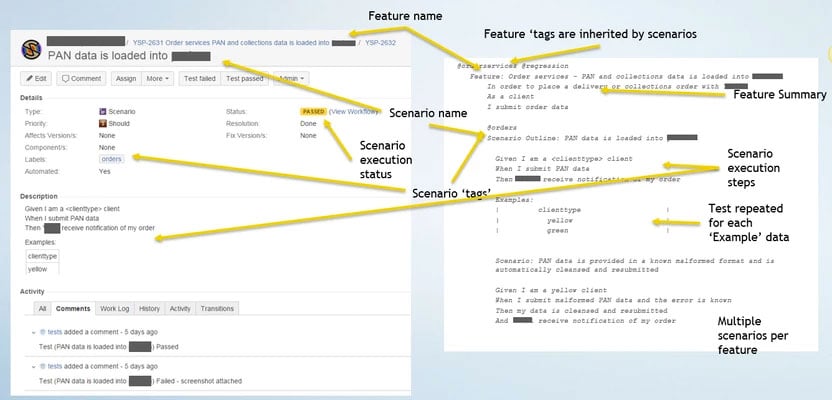
As you might guess, you’ll create the dynamic feature files before a Cucumber JVM runner executes the tests. To make this easier, we’ve written a custom class BuildFeatures.class, that’s executed by Jenkins before the Cucumber TestRunner. It works like this; first, it fetches the scenarios from Jira, through a search function. Then, it writes the feature file, in the correct format, into the project or target directory.
package com.infomentum.utilities;
public class BuildFeatures {
private static String projectKey = System.getProperty("PROJECT_KEY");
private static String issueType = System.getProperty("ISSUE_TYPE"));
public static void main(String[] args) throws Exception {
try {
com.infomentum.utilities.TestResults.buildFeatureFiles(projectKey, issueType);
System.exit(0);
}
catch (Exception e) {
System.out.println(e.getMessage());
System.out.println(e.getStackTrace().toString());
System.out.println("Unable to update scenarios");
System.exit(0);
}
}
}
This function takes in a parameter, which is the Jira project issue code. We use this code to execute a query within the Jira instance, which identifies all of the automated features within the target project. I’ll tell you more about this is in a bit. After this first step, we iterate each issue in the result set, to determine the automated child scenarios of each feature. This step lets us exact the key information that’s required to populate the .feature file.
For each given feature in Jira, we create a new file in the target directory, using the feature description as the filename. We then populate this file - first with details from the feature, including the headline, description, and any labels. The Jira labels are used as the Cucumber @annotations for defining test sets. We then populate the details of each scenario related to the feature, one at a time. This includes the headline, the descriptions (the Given, When, Then statements), and again, the labels used as @annotations.
public static void buildFeatureFiles(String projectKey, String issueType) throws Exception {
String startPath = "target//generated-data//features//" + projectKey + "//";
// new instance of the jira helper
IMJiraHelper jira = new IMJiraHelper("Oauth");
// retreive all features from jira
Map<Map<String,String>,List<Map<String,String>>> allIssuesAndSubTasks = jira.getAllIssuesAndSubTasks(projectKey, issueType);
Set<Map<String,String>> features = allIssuesAndSubTasks.keySet();
// a counter for the features
int featureCounter=1;
// loop through all of the found features
for (Iterator<Map<String,String>> featureIt = features.iterator(); featureIt.hasNext(); ) {
Map<String,String> feature = featureIt.next();
// if the feature is automated
if (feature.get("Automated").equals("Yes")) {
// feature name
String featureName = feature.get("Summary").toLowerCase();
featureName = featureName.replace(" ", "-");
// tags
String[] tags = feature.get("Labels").split(",");
// create the feature file
String outfile = feature.get("Counter")+"-"+featureName+".feature";
// create the new file
File file = new File(startPath + outfile);
file.getParentFile().mkdirs();
FileWriter fw = new FileWriter(file, false);
// creater the print writer
PrintWriter pw = new PrintWriter(fw, true);
int tagsCounter=0;
pw.write("@"+feature.get("IssueKey"));
tags = feature.get("Labels").split(",");
// loop through each label
while (tagsCounter<tags.length) {
// remove unwanted characters from the jira labels
// for use in @tags
tags[tagsCounter]=tags[tagsCounter].replace("[", "");
tags[tagsCounter]=tags[tagsCounter].replace("]", "");
tags[tagsCounter]=tags[tagsCounter].replace(" ", "");
if(tags[tagsCounter].length()>2) {
pw.write(" @"+tags[tagsCounter]);
}
tagsCounter++;
}
pw.println();
// write the feature name
pw.write("Feature: " + feature.get("Summary"));
pw.println();
// write the featue description
if (feature.get("Description").equals("")) {
pw.println("No feature description");
}
else {
pw.write(feature.get("Description"));
}
pw.println();
// get all the scenarios for the feature
List<Map<String,String>> featureScenarios = allIssuesAndSubTasks.get(feature);
// loop through the found scenarios for each found feature
for (Iterator<Map<String,String>> scenarioIt = featureScenarios.iterator(); scenarioIt.hasNext(); ) {
pw.println();
// get the next scenario
Map<String,String> scenario = scenarioIt.next();
// only add the automated scenarios
if(scenario.get("Automated").equals("Yes")) {
// tags
pw.write("@"+scenario.get("IssueKey"));
tags = scenario.get("Labels").split(",");
tagsCounter=0;
while (tagsCounter<tags.length) {
tags[tagsCounter]=tags[tagsCounter].replace("[", "");
tags[tagsCounter]=tags[tagsCounter].replace("]", "");
tags[tagsCounter]=tags[tagsCounter].replace(" ", "");
if(tags[tagsCounter].length()>2) {
pw.write(" @"+tags[tagsCounter]);
}
tagsCounter++;
}
pw.println();
if(scenario.get("Description").contains("Examples")) {
pw.print("Scenario Outline: " + scenario.get("Summary"));
}
else {
pw.print("Scenario: " + scenario.get("Summary"));
}
pw.println();
pw.print(scenario.get("Description"));
pw.println();
}
}
//Flush the output to the file
pw.flush();
//Close the Print Writer
pw.close();
//Close the File Writer
fw.close();
}
// go to the next feature
featureCounter++;
}
}
A sample output is as follows:
@regression @eligibility @morningchecks
Feature: User enquires about their eligibility for the scheme
In order find out if I am eligible for the scheme
As a prospect
I complete the eligibility checker
@MO-212 @eligible @Blocker @Failed
Scenario: eligible visitor completes eligibility checker
Given I am eligible for the scheme
When I complete the eligibility checker
Then I get a positive outcome
@MO-213 @noteligible @Blocker @Passed
Scenario: not eligible visitor completes eligibility checker
Given I am not eligible for the scheme
When I complete the eligibility checker
Then I get a negative outcome
Note that the issue key, status and priority are also written as labels for each scenario. This lets us select to run an individual scenario, or re-run all failed scenarios, or all high-priority scenarios with ease.
3. Working with the Jira API
We used the Jira Java Rest Client (JRJC) for working with the Jira REST API, which comes with lots of useful methods for interacting with issues. The downside to this is that it isn't well-supported anymore. When we built features, we authenticated with Oauth. We had a great deal of “fun” with it, but got there in the end. To give you some extra help with this, I’m sharing a useful guide. Once you get that working, you deserve a coffee!
Not all JRJC functions seem to work when authenticating with Oauth, so we're still using basic authentication for transitioning and creating issues (more on this coming up below).
The following code block shows how we instantiate an instance of the Jira helper, using the preferred authentication type.
public IMJiraHelper(String authType) throws URISyntaxException {
super();
baseUrl = "https://ourjira.jira.com";
privateKey = "privatekey";
consumerKey = "OauthKey";
factory = new AsynchronousJiraRestClientFactory();
final URI jiraServerUri = new URI(baseUrl);
password = "password";
username = "username";
if (authType == "Oauth") {
restClient = factory.create(jiraServerUri, new AuthenticationHandler() {
@Override
public void configure(Request request) {
try {
OAuthAccessor accessor = getAccessor();
accessor.accessToken = "XXXXXXXXXXXXXXXXXXXXXX";
OAuthMessage request2 = accessor.newRequestMessage(null, request.getUri().toString(), Collections.<Map.Entry<?, ?>>emptySet(), request.getEntityStream());
Object accepted = accessor.consumer.getProperty(OAuthConsumer.ACCEPT_ENCODING);
if (accepted != null) {
request2.getHeaders().add(new OAuth.Parameter(HttpMessage.ACCEPT_ENCODING, accepted.toString()));
}
Object ps = accessor.consumer.getProperty(OAuthClient.PARAMETER_STYLE);
ParameterStyle style =
(ParameterStyle)((ps == null) ? ParameterStyle.BODY
: Enum.valueOf(ParameterStyle.class, ps.toString()));
HttpMessage httpRequest = HttpMessage.newRequest(request2, style);
for ( Entry<String, String> ap : httpRequest.headers)
request.setHeader(ap.getKey(), ap.getValue());
request.setUri( httpRequest.url.toURI() );
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
else {
try {
restClient = factory.createWithBasicHttpAuthentication(jiraServerUri, username, password);
}
catch (NullPointerException e) {
e.getMessage();
}
}
}
private final OAuthAccessor getAccessor()
{
if (accessor == null)
{
OAuthServiceProvider serviceProvider = new OAuthServiceProvider(getRequestTokenUrl(), getAuthorizeUrl(), getAccessTokenUrl());
OAuthConsumer consumer = new OAuthConsumer(callback, consumerKey, null, serviceProvider);
consumer.setProperty(RSA_SHA1.PRIVATE_KEY, privateKey);
consumer.setProperty("user_id", username);
consumer.setProperty("xoauth_requestor_id", username);
consumer.setProperty(OAuth.OAUTH_SIGNATURE_METHOD, OAuth.RSA_SHA1);
accessor = new OAuthAccessor(consumer);
}
return accessor;
}
private String getAccessTokenUrl()
{
return baseUrl + SERVLET_BASE_URL + "/oauth/access-token";
}
private String getRequestTokenUrl()
{
return baseUrl + SERVLET_BASE_URL + "/oauth/request-token";
}
public String getAuthorizeUrlForToken(String token)
{
return getAuthorizeUrl() + "?oauth_token=" + token;
}
private String getAuthorizeUrl() {return baseUrl + SERVLET_BASE_URL + "/oauth/authorize";}
Now that we have our Jira helper instance, we can start to use some of our custom methods. In BuildFeatures, you might have noticed a call to jira.getAllIssuesAndSubTasks(projectKey, issueType). This method uses our authenticated Jira session to execute the required query, by using Jira's JQL syntax. Then, it iterates the result set for each issue, to obtain the required information (first for the parent feature issue). Within that step, it finds all sub-tasks for each feature (the scenarios) and iterates those. Again, it grabs all the necessary attributes as it goes along.
We use the custom field above (“Automated”) to include only the features and scenarios which are automated. This is to select the ones to include in the feature, and which ones to ignore. Note that you have to reference it by field ID.
The returned object, (Map<Map<String,String>,List<Map<String,String>>>) is a Map. The Key is a Map itself, that maps the attribute name and value for the required data attributes from the feature. The value of the Map is a List of Maps, that contains the attribute names, and values, for each child scenario of the feature.
// get all issues and subtasks from a project of a certain type
public Map<Map<String,String>,List<Map<String,String>>> getAllIssuesAndSubTasks(String projectKey, String issueType) {
// holds the jira items mapping features to their scenarios
Map<Map<String,String>,List<Map<String,String>>> jiraItems = new HashMap<Map<String,String>,List<Map<String,String>>>();
// execute jql query in jira
Promise<SearchResult> searchJqlPromise = restClient.getSearchClient().searchJql("project = " + projectKey + " AND issuetype in (Epic, CucumberFeature) ORDER BY Rank ASC");
// counts the features
int featureCounter = 1;
// gets each issue in turn
for (BasicIssue issue : searchJqlPromise.claim().getIssues()) {
Map<String,String> feature = new HashMap<String,String>();
// get the issue unique key for the feature
feature.put("IssueKey", issue.getKey());
System.out.println("Getting parent issue: "+issue.getKey());
// get the full jira issue for the feature
Issue fullIssue = restClient.getIssueClient().getIssue(issue.getKey()).claim();
// get the issue summary
feature.put("Summary", fullIssue.getSummary());
// get the issue description
feature.put("Description", fullIssue.getDescription());
// get the issue labels
feature.put("Labels", fullIssue.getLabels().toString());
// add a feature counter to determine the order of execution
feature.put("Counter", Integer.toString(featureCounter));
// find out if the scenairo is automated
try {
IssueField field = fullIssue.getField("customfield_12610");
if(field.getValue().toString().contains("Yes")) {
feature.put("Automated", "Yes");
}
else {
feature.put("Automated", "No");
}
}
catch (Exception e) {
feature.put("Automated", "No");
}
// get all the issue subtasks
Iterable<Subtask> subtasks = fullIssue.getSubtasks();
int i=0;
// iterate over subtasks
Iterator subtasksIterator = subtasks.iterator();
List<Map<String,String>> scenarios = new ArrayList<Map<String,String>>();
while (subtasksIterator.hasNext()) {
Map<String,String> scenario = new HashMap<String,String>();
Subtask subtask = Iterables.get(subtasks, i);
// get the scenario summary
scenario.put("Summary", subtask.getSummary());
// get the feature issue key
scenario.put("IssueKey", subtask.getIssueKey());
// get the full issue for the scenario
System.out.println("Getting sub issue: "+ subtask.getIssueKey());
Issue fullSubtask = restClient.getIssueClient().getIssue(subtask.getIssueKey()).claim();
// add subtask description
scenario.put("Description", fullSubtask.getDescription());
// try to get the issue priority
String priority = "";
try {
priority = fullSubtask.getPriority().getName();
}
catch (Exception e) {
priority = "Blocker";
}
scenario.put("Priority", priority);
// add the task labels
scenario.put("Labels", fullSubtask.getLabels().toString());
// add the status
String status = fullSubtask.getStatus().getName().replace(" ", "").replace(".", "");
scenario.put("Status", status);
// add the fix version
String fixVersion = "";
try {
Iterator<Version> versionIterator = fullSubtask.getFixVersions().iterator();
while ((versionIterator.hasNext()) ) {
Version version = versionIterator.next();
fixVersion = fixVersion + version.getName()+",";
}
fixVersion = fixVersion.substring(0,fixVersion.length()-1);
}
catch (Exception e) {
fixVersion = "";
}
scenario.put("FixVersion", fixVersion);
// add priority to labels if present
if (priority!="") {
scenario.put("Labels", scenario.get("Labels") + "," + priority);
}
// add fix version to labels if present
if (fixVersion!="") {
scenario.put("Labels", scenario.get("Labels") + "," + fixVersion);
}
// add status to labels if present
if (status!="") {
scenario.put("Labels", scenario.get("Labels") + "," + status);
}
// find out if the scenairo is automated
try {
IssueField fieldSub = fullSubtask.getField("customfield_12610");
if(fieldSub.getValue().toString().contains("Yes")) {
scenario.put("Automated", "Yes");
}
else {
scenario.put("Automated", "No");
}
}
catch (Exception e) {
scenario.put("Automated", "No");
}
subtasksIterator.next();
scenarios.add(scenario);
i++;
}
jiraItems.put(feature,scenarios);
featureCounter++;
}
return jiraItems;
}
4. Updating (and creating) Jira issues following test execution
After executing each scenario, we update the status of the associated Jira issue, by using the workflow transitions I defined above. If it fails, we add a screenshot, and we can raise a defect if the failure isn’t a known existing issue. On top of that, we add the status, build number, and the reason for failure to a comment, so we can maintain the execution history.
We use the @After hook within the StepDefinitions file, to call a function that updates the test status of the Jira issue, after each test scenario is executed.
@After
public void cleanUp(Scenario scenario) throws Exception {
results.Update(scenario, jira, projectName, environment, HIPCHAT_KEY, TEST_ROOM_ID, selenium.stackTrace, selenium.errorMessage, selenium.screenshot, true);
}
- First of all, we seek out the Jira issue reference from the list of labels, which we use to locate the issue within Jira;
- After that, we capture any browser console logs, and write them into the Cucumber scenario report.
- We also send tracking events to Google Analytics, so that we can capture data about the tests. I've found that this is a handy way of tracking trends in both failed and passed tests, in any project, at any given time. Before we close the browser, we capture a screenshot. That way, if there’s a failure, it can be embedded in the Cucumber report.
- The next step is to transition the issue in Jira. We do this using the correct Jira workflow transition name, which will depend on whether the scenario passed or failed. You can also include a function that sends notifications to a Hipchat room if there’s a failure. We’re not using this, though, since Jira transition has a function for it as well.
// Executes after each scenario is run (passed or failed)
public void Update(Scenario scenario, String jira, String projectName, String environment, String HIPCHAT_KEY, String TEST_ROOM_ID, String stackTrace, String errorMessage, byte[] screenshot, boolean raiseBug) throws Exception {
// get the jira reference key
Collection<String> tags = scenario.getSourceTagNames();
String jiraRef = GetJiraRef(tags, jira);
String issueStatus = "";
String transition = "";
// write any browser console logs to the scenario
scenario.write(this.selenium.analyzeLog("SEVERE","").toString());
// send execution data to google analytics
List<String> event = new ArrayList<String>();
event.add(projectName + environment);
event.add(scenario.getName());
event.add(scenario.getStatus().toString());
event.add("0");
selenium.analytics(trackType.event, "", event);
// Save a screenshot
byte[] screenshotNew = selenium.closeTheBrowser(scenario.isFailed());
if (scenario.isFailed()) {
scenario.embed(screenshotNew, "image/png");
issueStatus = "Failed";
transition = "Test failed";
}
else {
issueStatus = "Passed";
transition = "Test passed";
raiseBug = false;
}
if (jiraRef != "") {
UpdateJira(transition, scenario, jiraRef, stackTrace, errorMessage, screenshotNew, raiseBug, jira, environment);
}
if (TEST_ROOM_ID != "") {
//NotifyHipchat(scenario, HIPCHAT_KEY, TEST_ROOM_ID, jiraRef);
}
}
private static String GetJiraRef(Collection<String> tags, String jira) {
// Check if the scenario is linked to a JIRA issue.
// If it is, the first scenario tag is extracted as the JIRA reference
String[] myStringArray = tags.toArray(new String[0]);
String jiraRef = "";
int i = 0;
String allTags = "";
if (myStringArray.length == 0) {
allTags = "Unknown";
} else {
while (i < myStringArray.length) {
if (myStringArray[i].length()>jira.length()) {
if ((myStringArray[i].substring(1,jira.length() + 1).equals(jira))) {
jiraRef = myStringArray[i].substring(1);
}
}
allTags = allTags + " " + myStringArray[i];
i++;
}
}
return jiraRef;
}
We’re currently using basic authentication to update Jira issues, and we’re using the JRJC library to support the issue operations. To begin with, the issue is located by using the JiraRef (captured above). If the scenario fails, we attach the screenshot that we previously captured. Then, we construct a comment with the status of the scenario, and the stack trace of the exception. This comment is added to the issue as part of the transition action. In the case of failure, when updating Jira, a defect can optionally be created. In this case, the newly created issue is linked to the scenario.
private void UpdateJira(String transition, Scenario scenario, String jiraRef, String stackTrace, String errorMessage, byte[] screenshot, boolean raiseBug, String projectKey, String environment) throws Exception {
// If the scenario is linked to a JIRA issue, initialise the JIRA helper
IMJiraHelper iMJiraHelper = null;
String comment = "";
try {
iMJiraHelper = new IMJiraHelper("Basic");
}
catch (URISyntaxException e) {
System.out.println(e.getMessage());
}
assertTrue("IMJiraHelper not initialized correclty!!!", iMJiraHelper != null);
// Get the associated JIRA Issue
try {
Issue issue = iMJiraHelper.getIssue(jiraRef);
if (issue != null) {
// If the scenario is failed, update the JIRA issue status to failed and attach a screenshot
if (transition.equals("Test failed")) {
if (screenshot!=null) {
URI attachUri = issue.getAttachmentsUri();
try {
iMJiraHelper.attachScreenshot(attachUri, screenshot);
}
catch (URISyntaxException e) {
System.out.println(e.getMessage());
}
}
comment = "Test (" + scenario.getName() + ") Failed against build number " + System.getProperty("BUILD_NUMBER") +". See " + System.getProperty("BUILD_URL") + " for more details.";
if (stackTrace!=null) {
comment = comment + stackTrace;
}
if (raiseBug == true) {
//String newIssue = CreateJiraIssue(projectKey,scenario.getName(),errorMessage,stackTrace,screenshot);
String newIssue =iMJiraHelper.createIssue(projectKey, scenario.getName(), errorMessage, stackTrace, screenshot, environment);
System.out.println("New defect raised : " + newIssue);
iMJiraHelper.linkIssues(newIssue,jiraRef,"Testing defect");
}
}
if (transition.equals("Test passed")) {
comment = "Test (" + scenario.getName() + ") Passed against build number " + System.getProperty("BUILD_NUMBER") +". See " + System.getProperty("BUILD_URL") + " for more details.";
}
// Transition the issue
iMJiraHelper.transitionIssue(issue, comment, transition);
}
}
catch (RestClientException r) {
System.out.println(r.getMessage());
System.out.println("Issue not found");
}
}
The issue transition is identified by name, and the transition actioned.
public void transitionIssue(Issue issue, String comment, String transitionName) throws Exception {
// now let's start progress on this issue
final Iterable<Transition> transitions =
restClient.getIssueClient().getTransitions(issue.getTransitionsUri()).claim();
final Transition resolveIssueTransition =
getTransitionByName(transitions, transitionName);
if (resolveIssueTransition != null) {
restClient.getIssueClient().transition(issue.getTransitionsUri(),
new TransitionInput(resolveIssueTransition.getId(),
Comment.valueOf(comment)));
} else {
System.out.println("Issue transition not found");
}
}
private static Transition getTransitionByName(Iterable<Transition> transitions,
String transitionName) {
for (Transition transition : transitions) {
if (transition.getName().equals(transitionName)) {
System.out.println(transition.getName());
return transition;
}
}
return null;
}
Each time we create a new Jira issue, we check if there’s already another issue with the same summary description. We do this so that the same failure isn’t raised as a new defect on each run. Assuming it doesn't already exist, we then populate the description of the new issue with details from the stack trace. Other mandatory attributes are also populated. After the issue is created, we attach the screenshot of the failure to the issue and the issue key is returned so that it can be used to link the defect to the test scenario.
// create a new issue in jira for a failed test
public String createIssue(String projectKey, String scenario, String message, String stackTrace, byte[] attachment, String environment) throws Exception {
final IssueRestClient issueClient = restClient.getIssueClient();
final Iterable<CimProject> metadataProjects =
issueClient.getCreateIssueMetadata(new GetCreateIssueMetadataOptionsBuilder().withProjectKeys(projectKey).withExpandedIssueTypesFields().build()).claim();
// select project and issue
assertEquals(1, Iterables.size(metadataProjects));
final CimProject project = metadataProjects.iterator().next();
final CimIssueType issueType = EntityHelper.findEntityByName(project.getIssueTypes(), "Bug");
String description = "";
if (stackTrace != null) {
if (stackTrace.length() > 200) {
description = "Failed cucumber scenario: " + scenario + " : " + message + stackTrace.subSequence(0, 200);
}
else {
description = "Failed cucumber scenario: " + scenario + " : " + message + stackTrace;
}
}
else {
description = "Failed cucumber scenario: " + scenario;
}
final String summary = "Failed cucumber scenario: " + scenario;
// check if the isuse has already been raised
Promise<SearchResult> searchJqlPromise = restClient.getSearchClient().searchJql("project = " + projectKey + " AND status != Done AND issuetype = " + issueType.getName() + " AND summary ~ \"" + summary + "\" ORDER BY Rank ASC");
System.out.println("project = " + projectKey + " AND status != Done AND issuetype = " + issueType.getName() + " AND summary ~ \"" + summary + "\" ORDER BY created DESC");
boolean found = false;
String existingIssueKey = "";
// gets each issue in turn
if (searchJqlPromise.claim().getTotal() > 0) {
existing:
for (BasicIssue issue : searchJqlPromise.claim().getIssues()) {
Issue fullIssue = restClient.getIssueClient().getIssue(issue.getKey()).claim();
// get the issue description
//if (fullIssue.getDescription().equals(description)) {
found = true;
existingIssueKey = fullIssue.getKey();
break existing;
//}
}
}
if (found == false) {
System.out.println("No existing issue");
// grab the first priority
final Iterable<Object> allowedValuesForPriority = issueType.getField(IssueFieldId.PRIORITY_FIELD).getAllowedValues();
assertTrue(allowedValuesForPriority.iterator().hasNext());
BasicPriority priority = (BasicPriority)allowedValuesForPriority.iterator().next();
// get allowed value for tempo account id
Iterable<Object> allowedValues = issueType.getFields().get("customfield_11610").getAllowedValues();
String accountId = (allowedValues.iterator().next().toString());
accountId = accountId.substring(accountId.indexOf(":")+1, accountId.indexOf(","));
// build issue input
// prepare IssueInput
final IssueInputBuilder issueInputBuilder = new IssueInputBuilder(project, issueType,summary)
//.setFieldValue("customfield_11610", ComplexIssueInputFieldValue.with("id","125"))
.setFieldValue("customfield_11610", "125")
.setDescription(description)
//.setComponents(component)
.setPriority(priority)
.setFieldValue("labels",Arrays.asList("AutomatedTest", "Cucumber", environment));
// create
final BasicIssue basicCreatedIssue = issueClient.createIssue(issueInputBuilder.build()).claim();
assertNotNull(basicCreatedIssue.getKey());
// get issue and check if everything was set as we expected
final Issue createdIssue = issueClient.getIssue(basicCreatedIssue.getKey()).claim();
assertNotNull(createdIssue);
URI attachmentsUri = createdIssue.getAttachmentsUri();
attachScreenshot(attachmentsUri, attachment);
return createdIssue.getKey();
}
else {
return existingIssueKey;
}
}
// attach a screenshot to jira issue
public void attachScreenshot(URI uri, byte[] attachment) throws Exception {
String attachmentText = new String(attachment, "UTF-8");
if (attachmentText.equals("Screenshot not available")==false) {
restClient.getIssueClient().addAttachment(uri,
new ByteArrayInputStream(attachment),
"screenshot.png").claim();
}
}
// links two jira issues and any story linked to the original issue
public void linkIssues(String issueOne, String issueTwo, String linkName) throws Exception {
final IssueRestClient issueClient = restClient.getIssueClient();
issueClient.linkIssue(new LinkIssuesInput(issueOne, issueTwo, linkName, null)).claim();
final Issue originalIssue = issueClient.getIssue(issueTwo).claim();
Iterator<IssueLink> links = (originalIssue.getIssueLinks().iterator());
while ((links.hasNext()) ) {
IssueLink link = links.next();
if (link.getIssueLinkType().getName().equals("Tests")) {
issueClient.linkIssue(new LinkIssuesInput(issueOne, link.getTargetIssueKey(), linkName, null)).claim();
}
}
}
A few "gotcha" moments
- Import SSL certs. to the certificate truststore. Many Jira instances are served over HTTPS, and you'll need to import the certificate into the trust store in the $JAVA_HOME of wherever you are executing from;
- Jira Access permissions - the user who's using the Jira API will need the following permissions on each project you are working with: Browse project, Add comment, Transition, Update issue, Create issue, Link issues, Add attachment;
- Oauth authentication - oauth authentication is not fully supported by JRJC, so we are still using basic authentication for some operations.
Running from Jenkins
Of course we want to run all of this from Jenkins, which is where our Jenkinsfile comes into play.
if (FETCHJIRATESTS=="true") {
stage 'GetTests'
sh 'rm SeleniumWorkspace/SeleniumTests/target/generated-data/features/**/*.feature || echo "No features to delete"'
sh 'mvn exec:java -f SeleniumWorkspace/SeleniumTests/pom.xml -Dexec.mainClass="com.infomentum.utilities.BuildFeatures" -Dexec.classpathScope=test -DfailIfNoTests=false -Dtest=BuildFeatures -Dmaven.test.failure.ignore=true -Dgatling.skip=true -Dgatling.test.skip=true -DRESET_JIRA='+RESETJIRA+' -DPROJECT_KEY='+PROJECTJIRAKEY+' '
}
else {
sh 'echo Getting tests not required'
}
...
if (FUNCTIONALTEST=="true") {
stage('Functional test') {
wrap([$class: 'Xvfb', additionalOptions: '', assignedLabels: '', autoDisplayName: true, debug: true, installationName: 'xvfb', screen: '1366x768x24', shutdownWithBuild: true, timeout: 60]) {
sh 'mvn test -f SeleniumWorkspace/SeleniumTests/pom.xml -Dtest='+TESTRUNNER+' \"-Dcucumber.options=--tags '+SUITES+' '+TESTTAGS+'\" -DfailIfNoTests=false -Denvironment='+ENVIRONMENT+' \"-Dbrowser='+BROWSER+'\" -DBUILD_NUMBER=${BUILD_NUMBER} -DBUILD_URL=${BUILD_URL} -Dmaven.test.failure.ignore=true'
}
step([$class: 'CucumberReportPublisher', fileExcludePattern: '*-usage.json', fileIncludePattern: '*.json', ignoreFailedTests: true, jenkinsBasePath: '', jsonReportDirectory: 'SeleniumWorkspace/SeleniumTests/target', missingFails: false, parallelTesting: true, pendingFails: false, skippedFails: false, undefinedFails: false])
junit 'SeleniumWorkspace/SeleniumTests/target/cucumber-junit.xml'
}
}
else {
sh 'echo Functional test not required'
}
Stay tuned as more exciting information is coming soon.
Wrapping up...
I didn't write this as a full how-to guide; it's more of an overview of how we utilise Jira. If you'd like help with anything else, please get in touch!
In my next article, I'll talk about how we use this framework to run automated security vulnerability scans.
.png)