
In the 'What are microservices (part 3)' we touched different approaches to building a microservices architecture. In this final post of series on microservices, I will discuss those approaches in more details.
Recent Posts
Tech
Microservices: decomposing monolith and what can go wrong

Wait! Have you read 'What are microservices' blog posts part 1 and part 2? You need to cover those out before reading on.
When it comes to microservices, the million dollar question is: “How do I decompose my monolith into microservices?”. Well, as you can imagine this can be done in many ways, and here I will be suggesting some guidelines.
Tech
Are microservices really SOA in disguise?
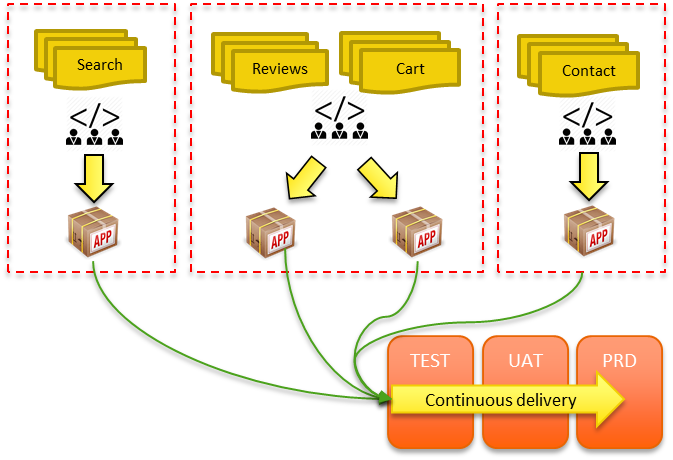
I’m going to pick up from last week’s post when we discussed the microservices definition, and looked at the alternative approach to microservices, aka the monolith. Make sure you read that before carrying on with this post.
Why is the microservices approach different? Let’s explore the main features one by one.
Tech
What are microservices?
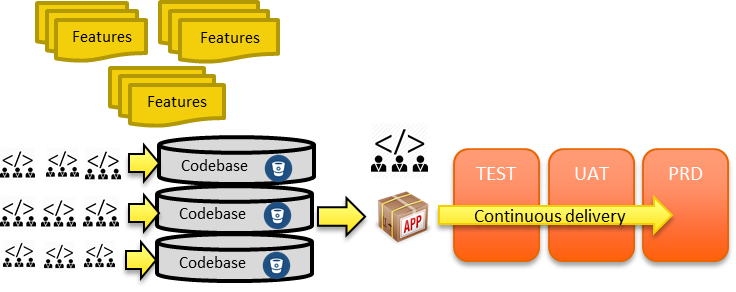
The discussion on microservices has exploded recently. It’s been heralded as the future. But is it really so new, or something more familiar than we think?
Well, let’s start by setting the scene; what are microservices?
