

As a Test Analyst at Infomentum, I generally follow a formal structured test process, one that is promoted by certification bodies such as ISTQB. It ensures that we adhere to the best practices and verify that the software under test meets our requirements. But is it always enough? In my experience, no. On occasion, a more experimental method of testing is a more suitable approach for that given project. Great news, it also fits nicely with an agile development cycle!
Tech
MuleSoft TDD with the use of MUnit
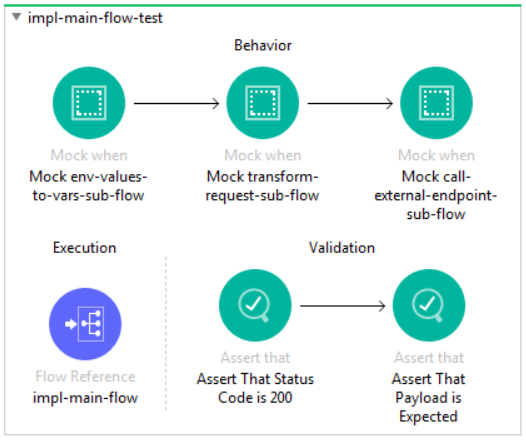
Unit testing has always been an integral part of software engineering because it ensures that problems in the code are isolated and fixed long before they become an issue in production. With the introduction and adoption of Agile framework, unit testing has changed dramatically because of the test-driven development (TDD) methodology. TDD is a software development strategy in which unit tests are used to drive the development process. In this blog, I explain how to practice TDD and share some tips on how to write great unit tests using MUnit.
Business
Innovative Test Automation Recognised at European Software Testing Awards

Hot on the heels of their latest award from the UK Oracle User Group, Infomentum is announced as a contender for Best Test Automation Project at the European Software Testing Awards.
Infomentum was selected for the shortlist after sharing an innovative automotive customer story. The project demanded complex, bespoke simulation of an end-to-end car diagnostics scan, offering significant challenges for the test team to overcome. The achievements made by the team were recognised by the awards judges.
