Wait! Have you read 'What are microservices' blog posts part 1 and part 2? You need to cover those out before reading on.
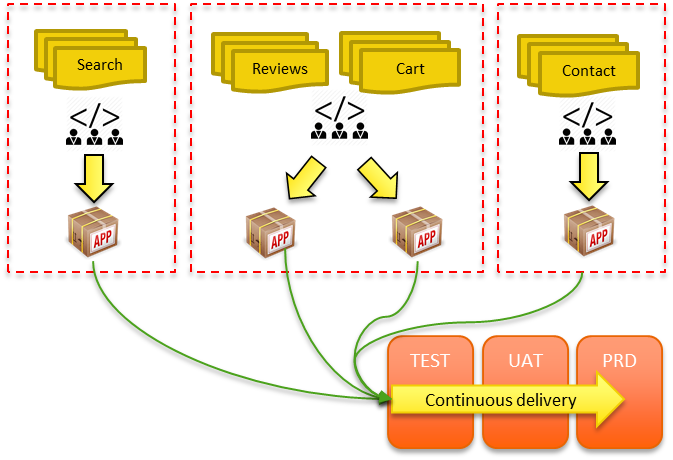
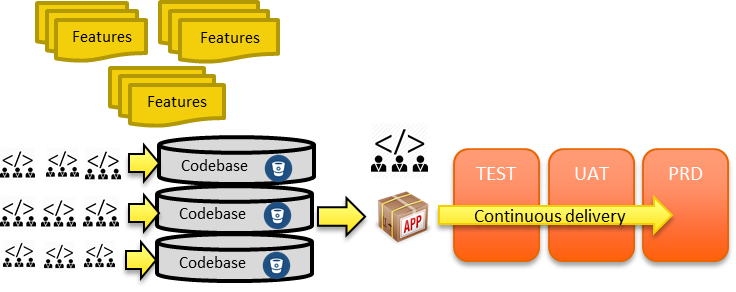
When it comes to microservices, the million dollar question is: “How do I decompose my monolith into microservices?”. Well, as you can imagine this can be done in many ways, and here I will be suggesting some guidelines.