
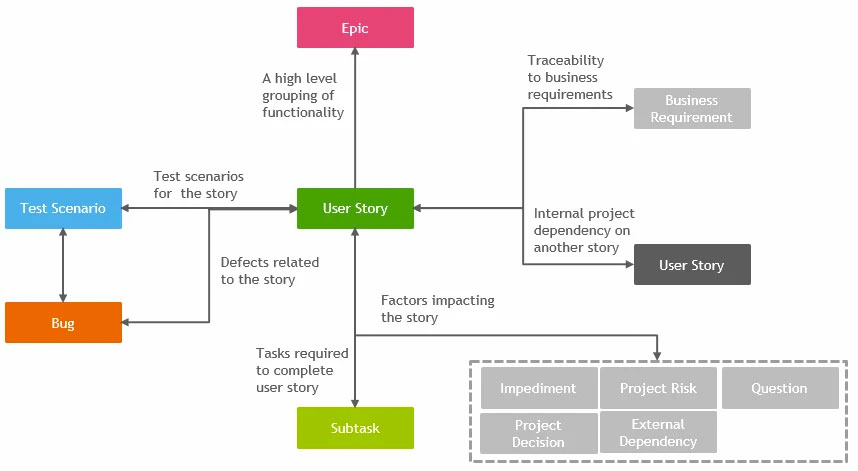
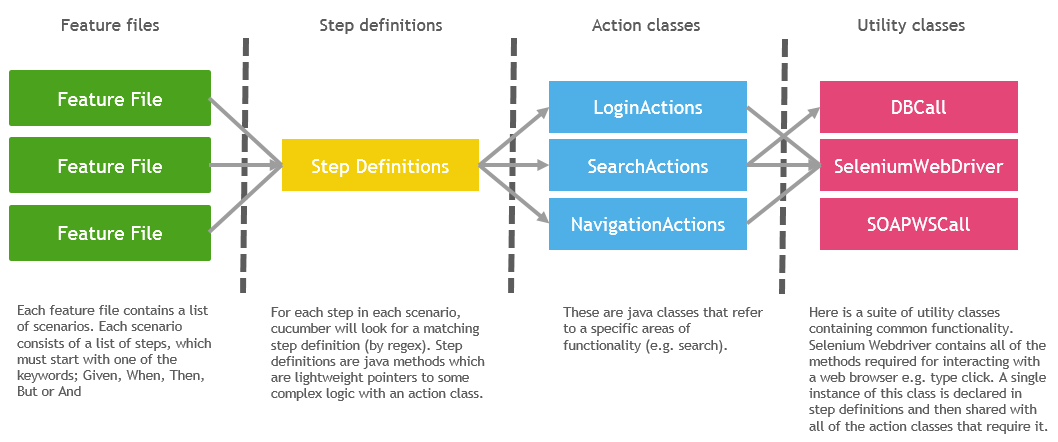
In my last article, The evolution of test documentation; lessons learned from implementing Cucumber, I explained two things. Firstly, how we at Infomentum have adopted Behaviour-Driven Development to define test scenarios, and secondly, how we use Cucumber JVM as an implementation platform for running these scenarios as automated tests.
Recent Posts
Business
The evolution of test documentation; lessons learned from implementing Cucumber
The old way
I'm going to let you in on a secret. I learnt my trade in a traditional software testing consultancy - I'm talking a waterfall approach to test planning, test case definition and test scripting. Over the last 5 years at Infomentum, I've evolved and have worked hard to optimise Infomentum's testing practices to suit our agile development environment.
